




多言語・長文コンテキスト推論AI「SmolLM3」をHugging Faceがリリース、パラメータの少ない小規模言語モデルでありながらより大規模な言語モデルの性能に匹敵

AIのモデルやデータを共有するオープンソースプラットフォームのHugging Faceは、言語モデルの「Smol」の最新バージョンである「SmolLM3」を2025年7月8日に発表しました。SmolLM3は6言語の多言語対応および最大12万8000トークンの長文にも対応しており、ハイコンテキスト対応モデルとしては大幅に少ないパラメータ数で最先端レベルのパフォーマンスを実現しています。
SmolLM3: smol, multilingual, long-context reasoner
https://huggingface.co/blog/smollm3
SmolLM3
https://huggingface.co/docs/transformers/model_doc/smollm3
数千億~数兆ものトレーニングパラメータを持つ大規模言語モデル(LLM)は、より高い演算性能を発揮し、より良いコンテンツを生成できますが、その分膨大な計算能力が必須です。一方で、数百万から数十億の範囲で限られた環境でもトレーニングやホストが可能なAIは小規模言語モデル(SLM)と呼ばれます。
Hugging Faceの開発コミュニティは、個人用PCでAIモデルを動かす需要の高まりから、重要性が高まるSLMのスケールでの可能性を限界まで押し広げる小型モデルを数多く生み出しています。2025年7月8日にHugging Faceがリリースした「SmolLM3」は、SLMでありながらパフォーマンスにおいて一部のLLMを超える性能を発揮することができます。
SmolLM3は3Bパラメータの小型モデルです。「3B」とはAIモデルの規模を表す指標で、「3 Billion(30億)」というパラメータの数を表しています。例えば、大規模言語モデルのGPT-3は約1750億、GPT-4は数千億以上のパラメータ数と推定されており、30億のパラメータを持つSmolLM3は小型モデルに分類されます。
大規模言語モデルの開発者が知っておくと役立つさまざまな数字 - GIGAZINE

SmolLM3は英語、フランス語、スペイン語、ドイツ語、イタリア語、ポルトガル語の6言語に対応しています。また、最大12万8000トークンの長文にも対応。12万8000トークンは英文で約9万6000語で、300~400ページの本1冊分に相当するため、長い文章の要約や会話履歴の保持などに優れています。最大12万8000トークンはGPT-4と同等のトークン数であり、SLMとしては驚異的な数値といえます。
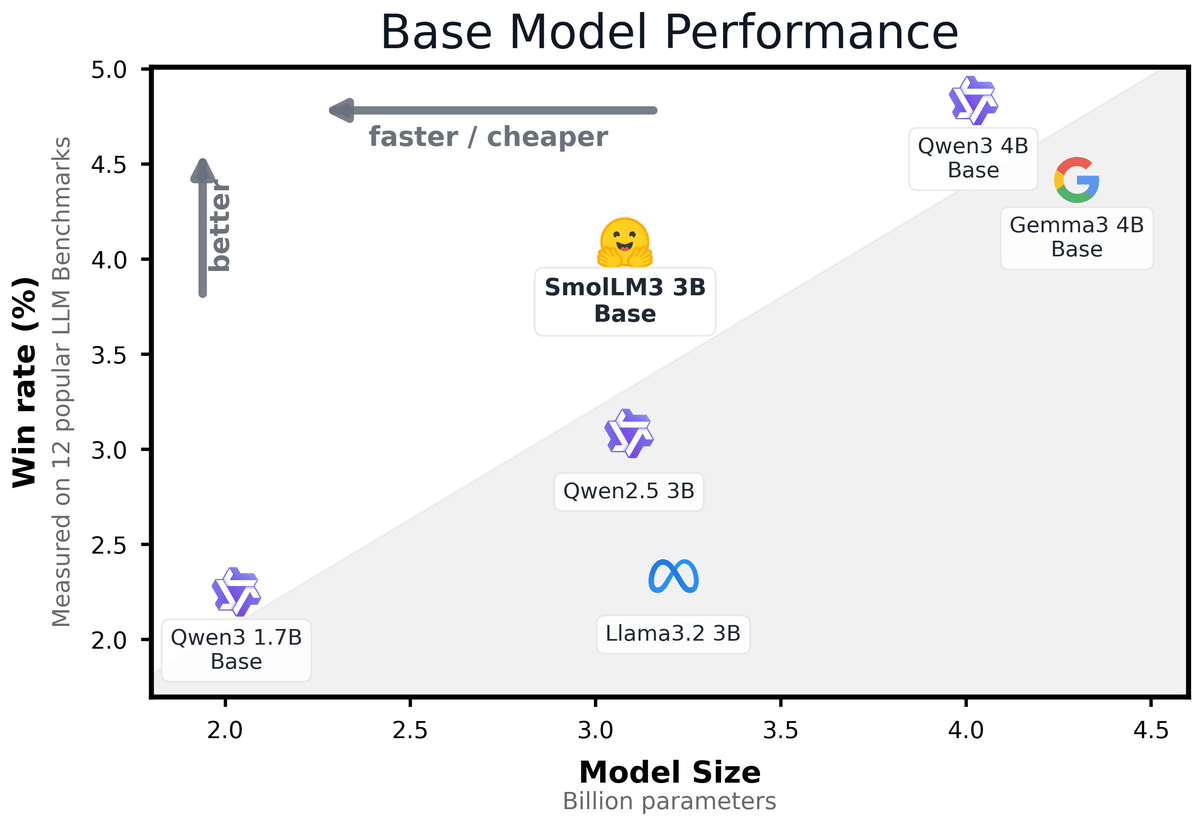
以下は、Hugging Faceが示したパフォーマンスに関するグラフです。グラフでは、知識、推論、数学、コーディング能力を評価する12の一般的なベンチマークにおける勝率を示しています。グラフによると、SmolLM3は同じ3BモデルであるAlibabaの「Qwen2.5 3B」やMetaの「Llama 3.2 3B」を一貫して上回り、より大規模な4Bモデルである「Qwen3 4B」や、「単一のGPUで実行できる中では過去最高の大規模言語モデル」と評されたGoogleの「Gemma 3 4B Base」と互角のパフォーマンスを発揮したとのこと。
SmolLM3が少ないパラメータで高い性能を発揮している理由のひとつが「3段階学習」というトレーニングプロセスです。段階学習とは、1回で全てのデータセットを学習させるのではなく、学習内容やデータ構成を段階的に変えながらトレーニングする方法のこと。SmolLM3では、第1段階では一般常識と自然言語の基礎を習得し、第2段階ではプログラミング能力と論理性の強化、第3段階では数学とコードにさらに重点を置いて応用力を強化するという3段階のトレーニングを実施しています。
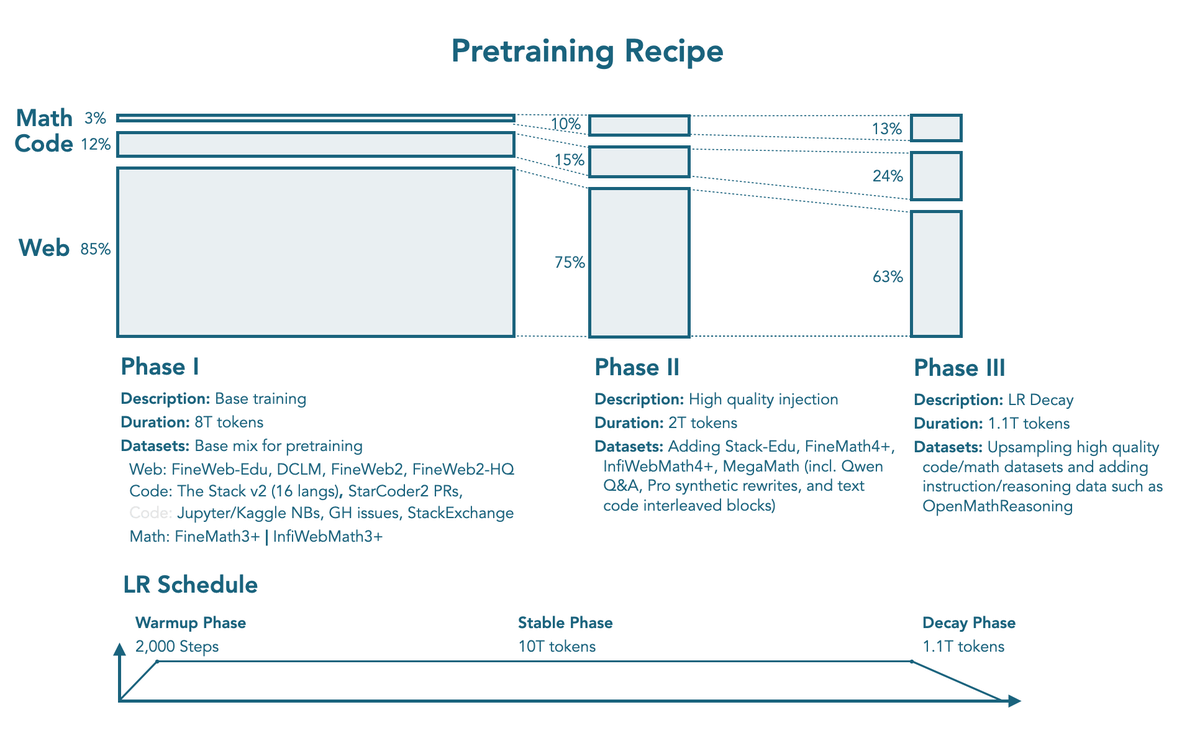
また、3Bモデルの多くは500億~1000億トークンでトレーニングされているのに対し、SmolLM3は11兆2000億というはるかに膨大なトークンを学習しており、このトレーニングに用いられたトークン数はGPT-3でも3000億程度のため、一部の大規模言語モデルも大きく上回っています。さらに、学習が進むごとに専門的なデータに絞る3段階学習を用いることで、効率的に学習してSLMでありながら高性能を実現しているというわけ。
その他の特徴として、SmolLM3には「/no_think」と「/think」という2つの「対話モード」があります。例えば計算問題をSmolLM3に回答させたとき、「/no_think」は素早く回答する代わりに計算過程は明示せず、答えのみ回答します。一方で「/think」の場合、「/no_think」より少し時間がかかりますが、「このように計算したためこういう回答になった」と理由を明示してくれます。トレーニングの中間学習において、段階的な推論プロセスを身に付けさせたことも、SmolLM3が高いパフォーマンスを発揮できる理由のひとつです。
SmolLM3はトレーニングプロセスを公開しており、合成データ生成を含む完全な学習レシピとデータセットも後日公開予定です。Hugging Faceは「このモデルがコミュニティにとって有用であり、他のグループがこのレシピを活用してモデルを改良していくことを期待しています」と述べています。
・関連記事
Hugging Faceでダウンロード可能なAIモデルの数が100万個を突破 - GIGAZINE
低コストで超高性能な「DeepSeek-R1」に似たAIモデルを誰でも開発できるようにオープンでない部分を補完するプロジェクト「Open-R1」をHugging Faceが始動 - GIGAZINE
高速推論が可能なレイテンシ重視AIモデル「Mistral Small 3」がリリースされる - GIGAZINE
Stability AIが新コーディング補助AI「Stable Code 3B」をリリース、少ないパラメーター数ながらMetaの「Code Llama 7B」と同等の性能を発揮 - GIGAZINE
Mistral AIがデバイス向け小規模モデル「Ministral 3B」「Ministral 8B」をリリース - GIGAZINE
AMDがAMD製GPUでトレーニングしたオープンソースの言語モデル「Instella」をリリース、同等モデルより高性能 - GIGAZINE
・関連コンテンツ
in ソフトウェア, Posted by log1e_dh
You can read the machine translated English article Hugging Face releases multilingual, long….