Hugging Face releases multilingual, long-text context inference AI 'SmolLM3,' a small-scale language model with few parameters that rivals the performance of larger language models

SmolLM3: smol, multilingual, long-context reasoner
https://huggingface.co/blog/smollm3
SmolLM3
https://huggingface.co/docs/transformers/model_doc/smollm3
Large-scale language models (LLMs) with hundreds of billions to trillions of training parameters can perform better and generate better content, but they require huge amounts of computing power. On the other hand, AI that can be trained and hosted in a limited environment with millions to billions of parameters is called a small language model (SLM) .
The Hugging Face development community has created many small models that push the limits of the scale possibilities of SLMs, which are becoming increasingly important due to the growing demand for running AI models on personal PCs. The 'SmolLM3', released by Hugging Face on July 8, 2025, is an SLM that can perform better than some LLMs.
SmolLM3 is a small model with 3B parameters. '3B' is an index that indicates the size of an AI model, and represents the number of parameters, '3 billion'. For example, the large-scale language model GPT-3 is estimated to have about 175 billion parameters, and GPT-4 is estimated to have more than several hundred billion parameters, so SmolLM3, which has 3 billion parameters, is classified as a small model.
Various numbers that are useful for developers of large-scale language models to know - GIGAZINE

SmolLM3 supports six languages: English, French, Spanish, German, Italian, and Portuguese. It also supports long texts of up to 128,000 tokens. 128,000 tokens is about 96,000 words in English, equivalent to a 300-400-page book, so it is excellent for summarizing long texts and retaining conversation history. The maximum number of tokens is the same as GPT-4, which is an astounding number for an SLM.
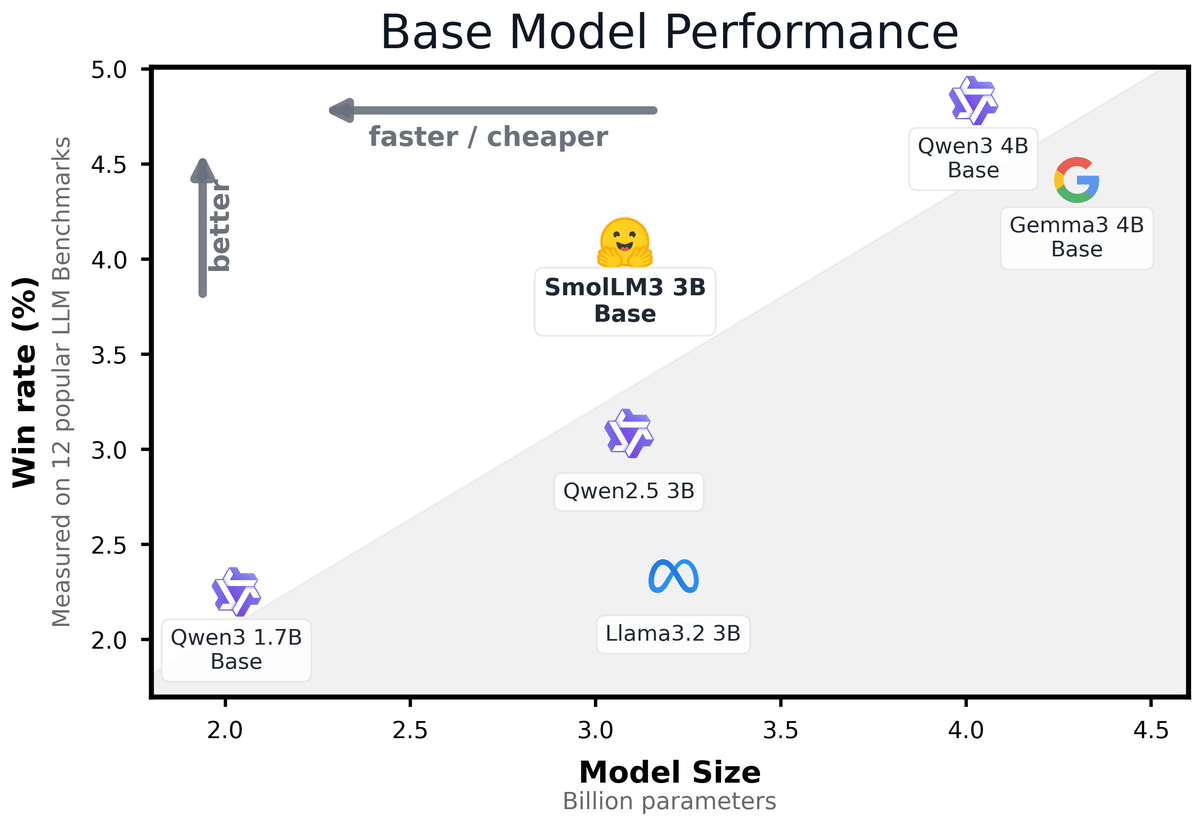
Below is a graph showing the performance shown by Hugging Face. The graph shows the win rate in 12 common benchmarks that evaluate knowledge, reasoning, mathematics, and coding ability. According to the graph, SmolLM3 consistently outperformed Alibaba's ' Qwen2.5 3B' and Meta's ' Llama 3.2 3B', which are the same 3B models, and performed on par with the larger 4B model ' Qwen3 4B' and Google's ' Gemma 3 4B Base', which was described as 'the largest large-scale language model ever to be run on a single GPU'.
One of the reasons why SmolLM3 achieves high performance with few parameters is the training process called 'three-stage learning'. Stage learning is a training method in which the learning content and data structure are changed step by step, rather than learning the entire dataset in one go. SmolLM3 conducts three stages of training: in the first stage, general knowledge and the basics of natural language are acquired, in the second stage, programming ability and logic are strengthened, and in the third stage, application skills are strengthened with a greater emphasis on mathematics and code.
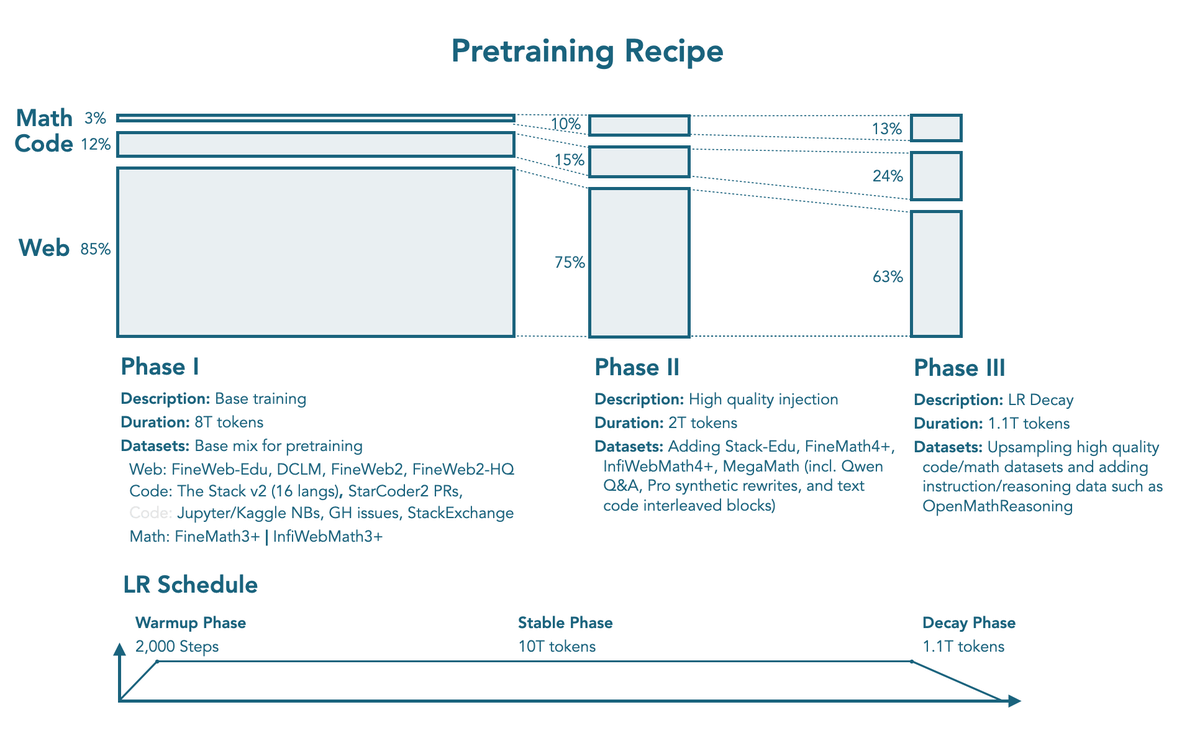
In addition, while most 3B models are trained with 50 to 100 billion tokens, SmolLM3 has learned a much larger number of tokens, 11.2 trillion, and the number of tokens used for this training is about 300 billion even for GPT-3, so it far exceeds some large-scale language models. Furthermore, by using three-stage learning that narrows down to specialized data as the learning progresses, it is possible to learn efficiently and achieve high performance despite being an SLM.
Another feature of SmolLM3 is that it has two 'interactive modes', '/no_think' and '/think'. For example, when you ask SmolLM3 to answer a calculation problem, '/no_think' will answer quickly, but will not reveal the calculation process, and will only give the answer. On the other hand, '/think' takes a little longer than '/no_think', but it will clearly explain the reason why, such as 'I calculated it like this, and this is the answer I got.' The fact that SmolLM3 has acquired a step-by-step reasoning process during intermediate learning in training is also one of the reasons why it can perform so well.
SmolLM3 has made the training process public, and the full learning recipe and dataset, including synthetic data generation, will be made public at a later date. Hugging Face says, 'We hope that this model will be useful to the community and that other groups will use this recipe to improve their models.'
in Software, Posted by log1e_dh