Google launches compact embedding model 'EmbeddingGemma,' using just 200MB of memory

Google has released an on-device
Introducing EmbeddingGemma: The Best-in-Class Open Model for On-Device Embeddings - Google Developers Blog
https://developers.googleblog.com/en/introducing-embeddinggemma/
EmbeddingGemma is our new best-in-class open embedding model designed for on-device AI. 📱
— Google DeepMind (@GoogleDeepMind) September 4, 2025
At just 308M parameters, it delivers state-of-the-art performance while being small and efficient enough to run anywhere - even without an internet connection. pic.twitter.com/QGDmTkOb1I
EmbeddingGemma is an embedding model consisting of approximately 100 million model parameters and approximately 200 million embedding parameters. Its highly efficient parameter design enables the construction of applications using techniques such as search expansion generation and semantic search that run directly on hardware. It is small, fast, and efficient, with customizable output dimensions and a 2K token context window, and is intended to operate offline on everyday devices such as mobile phones, laptops, and desktop PCs.
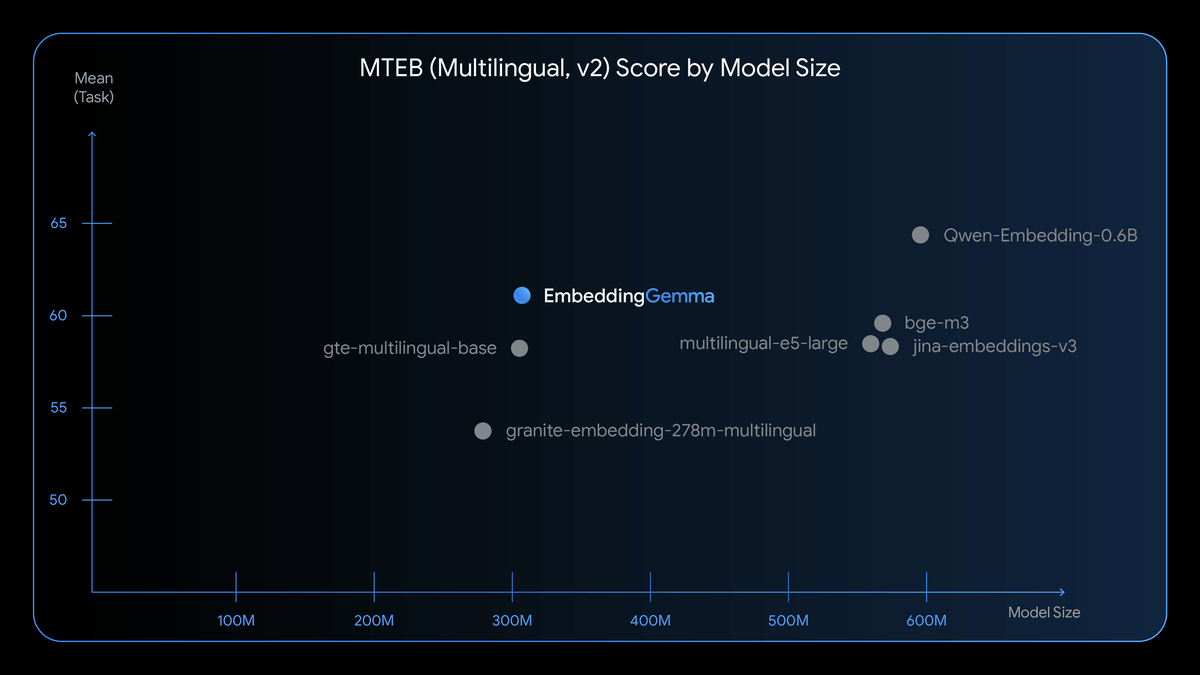
EmbeddingGemma has been trained in over 100 languages and uses a 'quantization' technique to reduce the size of the model by reducing the precision of the data, resulting in a model that is small enough to run on less than 200MB of RAM. Google CEO Sundar Pichai stated that EmbeddingGemma achieved the highest score of any open multilingual text embedding model with less than 500 million parameters in the benchmark 'MTEB,' which evaluates the performance of text embedding models.
Introducing EmbeddingGemma, our newest open model that can run completely on-device. It's the top model under 500M parameters on the MTEB benchmark and comparable to models nearly 2x its size – enabling state-of-the-art embeddings for search, retrieval + more.
— Sundar Pichai (@sundarpichai) September 4, 2025
The table below shows the MTEB scores. The horizontal axis is model size, and the vertical axis is score. The graph shows that EmbeddingGemma achieves performance comparable to models almost twice the size.
EmbeddingGemma is also unique in its construction of a Search Augmentation Generation (RAG) pipeline. The RAG pipeline has two key stages: obtaining relevant context based on user input, and generating answers based on that context. EmbeddingGemma guarantees the quality of the initial search step with high performance, providing the high-quality representations required for accurate and reliable on-device applications.
EmbeddingGemma is available for download from Hugging Face , Kaggle , and Vertex AI . You can find instructions on how to integrate EmbeddingGemma into your projects in Google's documentation .
in Software, Posted by log1e_dh