Building a search engine from scratch in just two months using 3 billion neural embeddings
Building a web search engine from scratch in two months with 3 billion neural embeddings
https://blog.wilsonl.in/search-engine/

Lin started his project to build a search engine from scratch because he believed that search engines were deteriorating due to an increase in search engine optimization (SEO) spam and a decrease in relevant, high-quality content. He wondered why search engines couldn't always display the highest quality content.
Lin also felt that search engines were lacking in performance. Most search engines are unable to display search results correctly for complex search queries . Lin wanted to build a search engine that could answer these questions.
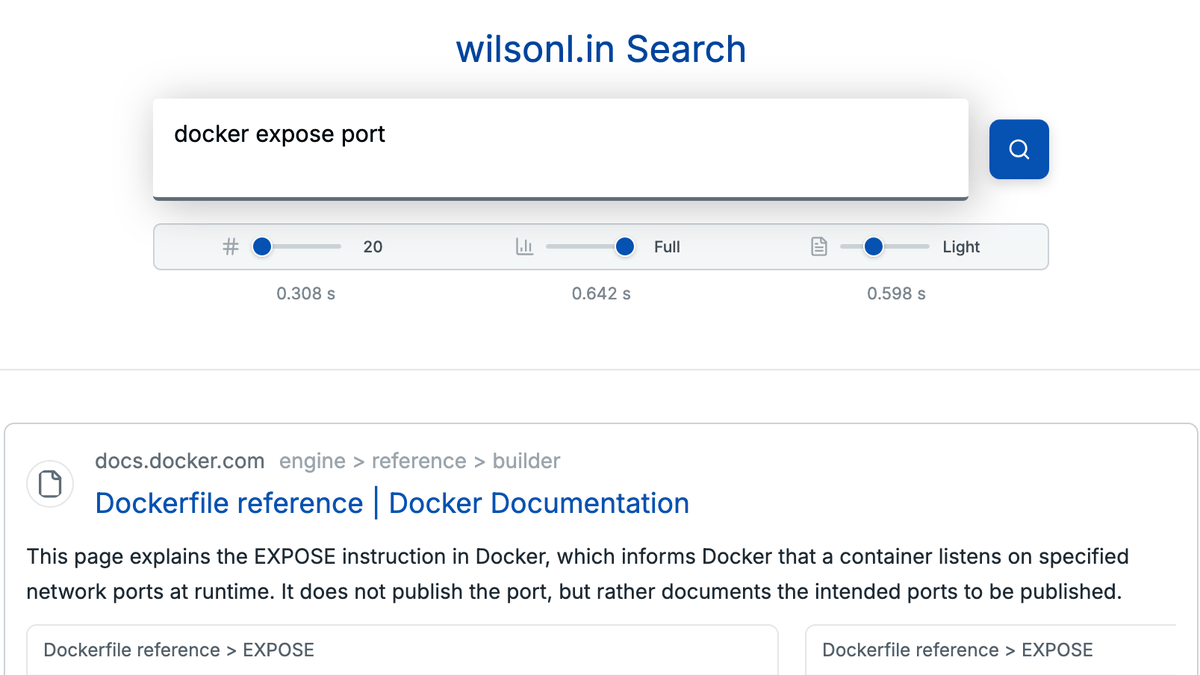
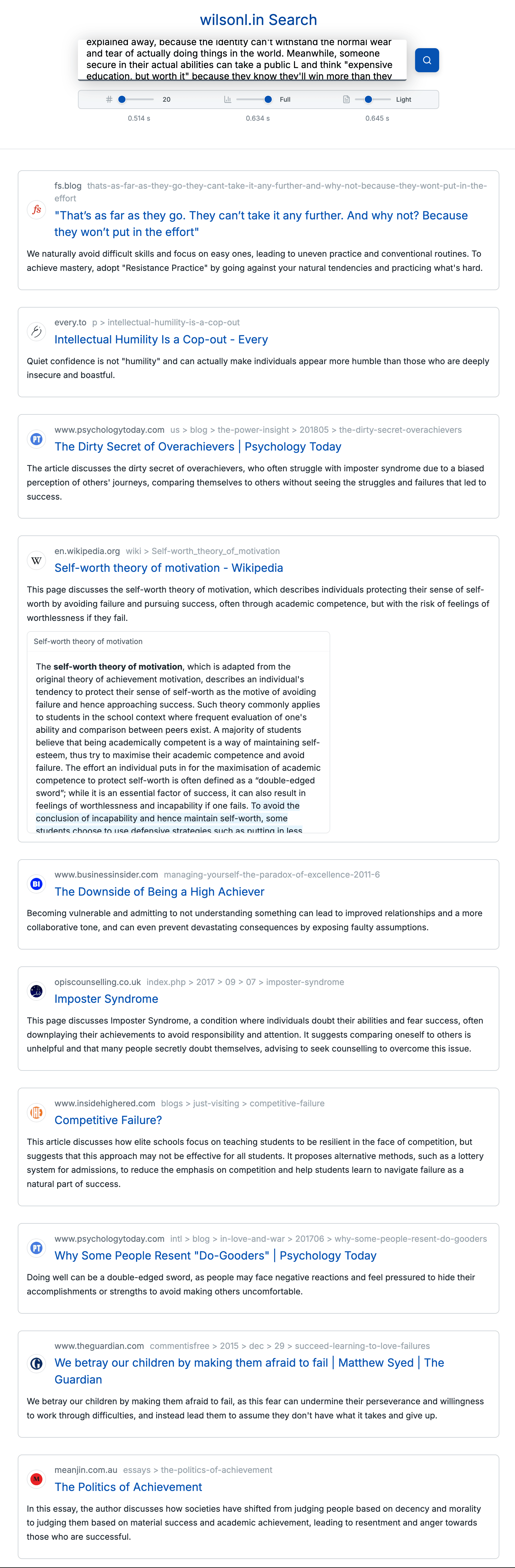
In fact, the search engine that Lin built can easily display search results even for long search queries.
Search engines are a technology that covers a wide range of fields, including computer science, linguistics,
The main features of the search engine built by Lin are as follows:
A total of 3 billion SBERT embeddings were generated using a cluster of 200 GPUs.
At its peak, hundreds of crawlers were ingesting 50,000 pages per second, and the search engine index reached 280 million results.
End-to-end query latency is approximately 500ms
RocksDB and HNSW are split across 200 cores, 4TB of memory (RAM), and 82TB of SSD.
You can actually try out a live demo version of the search engine that Lin built below.
wilsonl.in Search
https://search.wilsonl.in/
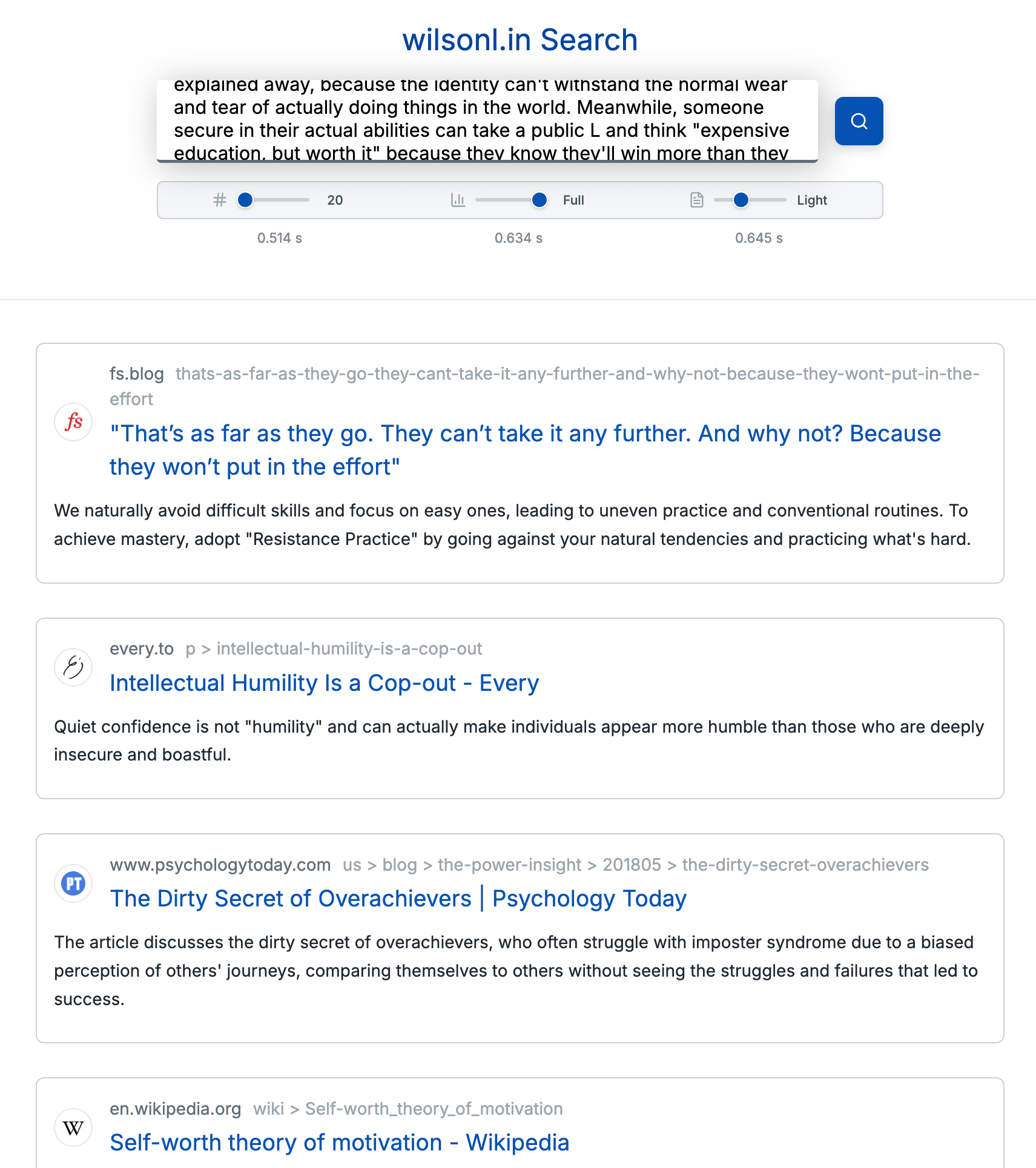
To test whether document embedding models ( neural embeddings ) like SBERT are good at search, Lin created a minimal playground by taking a few web pages, breaking them down into chunks, and testing whether they could accurately answer complex, indirect natural language queries.
For example, if you search for something like 'I want to use S3 instead of Postgres, but the database allows me to tag files with human comments in a separate column,' a traditional search engine would pick up appropriate keywords from the search query and return results related to Postgres, S3, and files. On the other hand, a search using neural embeddings can provide answers based on the user's search terms, such as 'You can also specify custom metadata when saving objects.'
Essentially, search engines need to understand the intent of a search, not just keywords. For example, if search queries can be used as long sentences rather than broken down into keywords or phrases, they will be less susceptible to keyword spam and SEO tactics. Lin also argued that search queries that include multiple concepts and nuances can be executed, allowing for complex relationships to be unravelled.
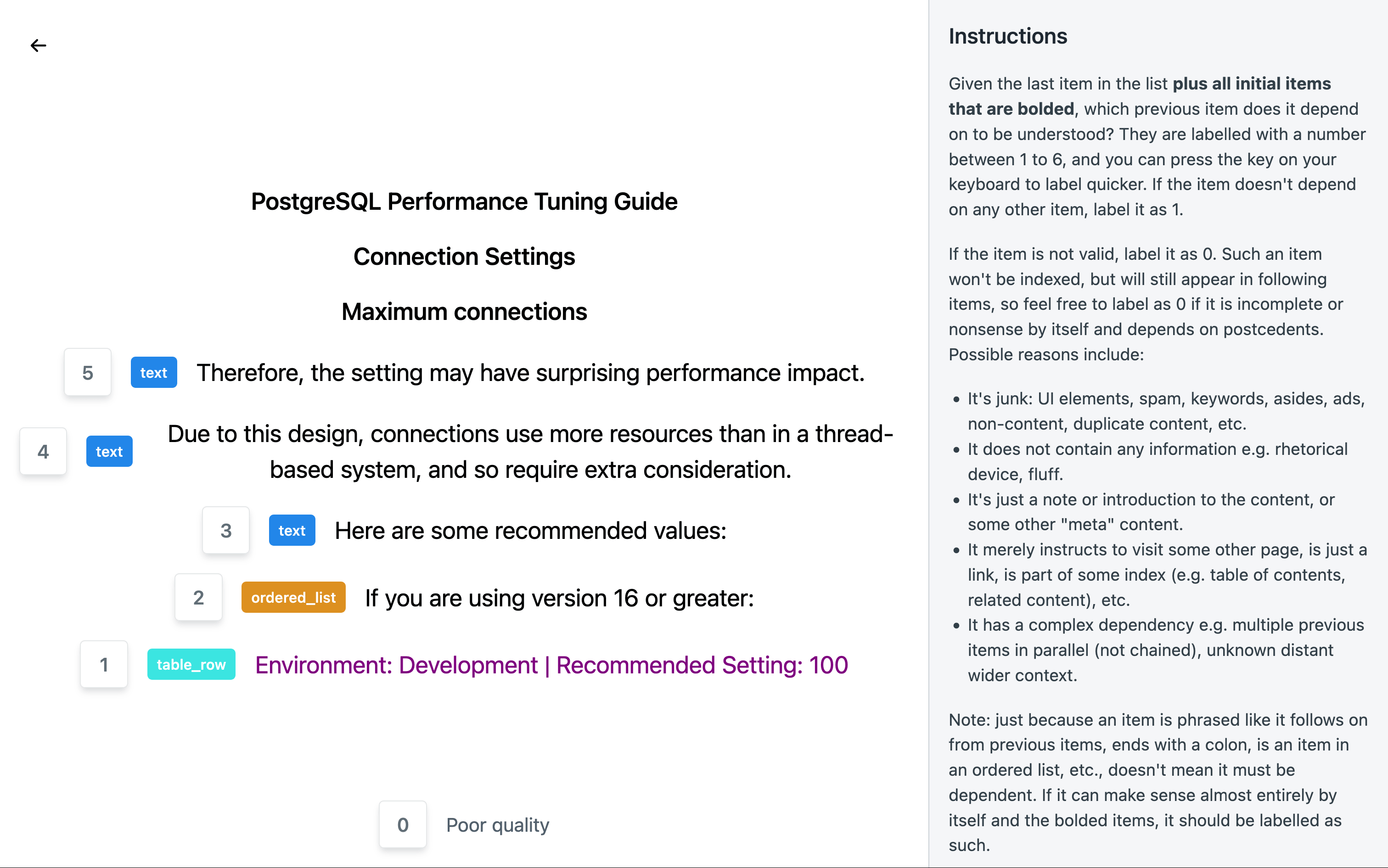
Furthermore, Lin points out that chunking is an important step when using neural embeddings to perform searches: most neural embeddings cannot handle entire page inputs and tend to lose expressiveness as search queries get longer.
A common approach is to simply split sentences into parts containing a few characters or words. However, this method can result in cluttered word, grammar, and structure, potentially compromising meaning. Instead, Lin used a pre-trained Sentencizer to split sentences into natural and consistent parts. Sentencizer is trained on a large text corpus and achieves high accuracy through a deep understanding of grammar and syntax. This allows it to better handle subtle nuances such as abbreviations, decimal points, URLs, and informal grammar in search queries.
A sentence is built based on previous sentences, paragraphs, and the concepts being discussed. Therefore, if a chunk is separated from the contextual structure, indirect references (such as 'that' or 'that') lose their meaning. Therefore, Lin uses a normalized semantic document tree.
However, this did not solve the problem of local context, such as sequelic sentences and anaphora, so Lin trained and utilized DistilBERT , a classification model that takes a sentence and its preceding sentence and labels which sentences (if any) it relies on to preserve meaning.
As a result, the search results pages of the search engine that Lin built have relatively little SEO spam, and are able to output appropriate search results even for very complex search queries (e.g., they can understand entire paragraphs about ideas).
In addition to using neural embedding for search and accurately splitting search queries, Lin also used a crawler to create the indexes necessary to build an actual search engine. Since using AI via an API was economically impossible, he built his own GPU. He has gone through various trial and error to build his own search engine.
in Software, Web Service, Posted by logu_ii