Training AI to be warm and empathetic makes it less trustworthy and more obsequious

As advanced conversational AI and task-specific AI agents develop, some AI developers are focusing not just on creating useful and safe models, but also on building human-like models that are 'friendly' and 'empathetic.' However, a paper published by researchers at the Oxford University Internet Institute reports that models trained on 'warmth' have problems, resulting in less reliable answers.
[2507.21919] Training language models to be warm and empathetic makes them less reliable and more sycophantic
AI is not just used to complete tasks, but is increasingly being used in supportive roles such as counseling and religious services . While one paper has shown that AI responses are perceived as more compassionate than those of human mental health professionals, there are also reports of AI therapy chatbots designed to please users exhibiting problematic behaviors that would be unthinkable for a human therapist, such as recommending drugs to recovering users of drug addiction.
Research finds that 'tactics to make AI more attractive' could lead AI chatbots to reinforce harmful beliefs like 'promoting drug use' - GIGAZINE

In his book Against Empathy: The Case for Rational Compassion, psychologist Paul Bloom argues that placing emphasis on empathy and compassion can cause problems in moral decision-making. According to Bloom, empathy is defined as 'the act of trying to experience the world as others experience it,' and while it can help people fill feelings of loneliness and anxiety, it may not align with moral judgment.

Similarly, there are concerns about the possibility that AI may make morally incorrect decisions due to its emphasis on empathy and compassion. Lujain Ibrahim and his colleagues at the Oxford University Internet Institute compared an empathetic AI model, known as a 'warm model,' trained on 'warmth' and 'friendliness,' with the original base model to evaluate its responses to various tasks.
The five AI models used in the experiment differed in size and structure: Llama-8B, Mistral-Small, Qwen-32B, Llama-70B, and GPT-4o. Each model was fine-tuned using supervised fine-tuning (SFT) to achieve a 'warm' representation using approximately 1,600 conversational datasets extracted from real conversations between humans and AI. The five base models and five warm models were then assigned objectively assessable tasks: general knowledge, veracity verification, resistance to misinformation, and medical advice, and the results were evaluated.
As a result, the warm model's error rate increased by 10 to 30% compared to the base model. In particular, in contexts where users expressed emotions such as 'sadness' or 'confusion,' the warm model's error rate increased even more, further reducing its reliability. Additionally, in conversations where users clearly believed false information, such as 'the capital of France is London,' the warm model was reported to have an increased tendency to flatter, confirming that false information.
The following diagram visualizes the 'flattery tendency' of the models. The horizontal axis shows the percentage of the base model that showed a tendency to flatter, and the vertical axis shows the percentage of the warm model that showed a tendency to flatter. To interpret the diagram, if the value overlaps the diagonal line, it means 'there is no change between the base model and the warm model,' and if it is above the diagonal line, it means 'after adjusting to the warm model, the tendency to flatter became stronger than the base model.' The diagram shows that the warm model showed a stronger tendency to flatter in all tasks for all AI models.
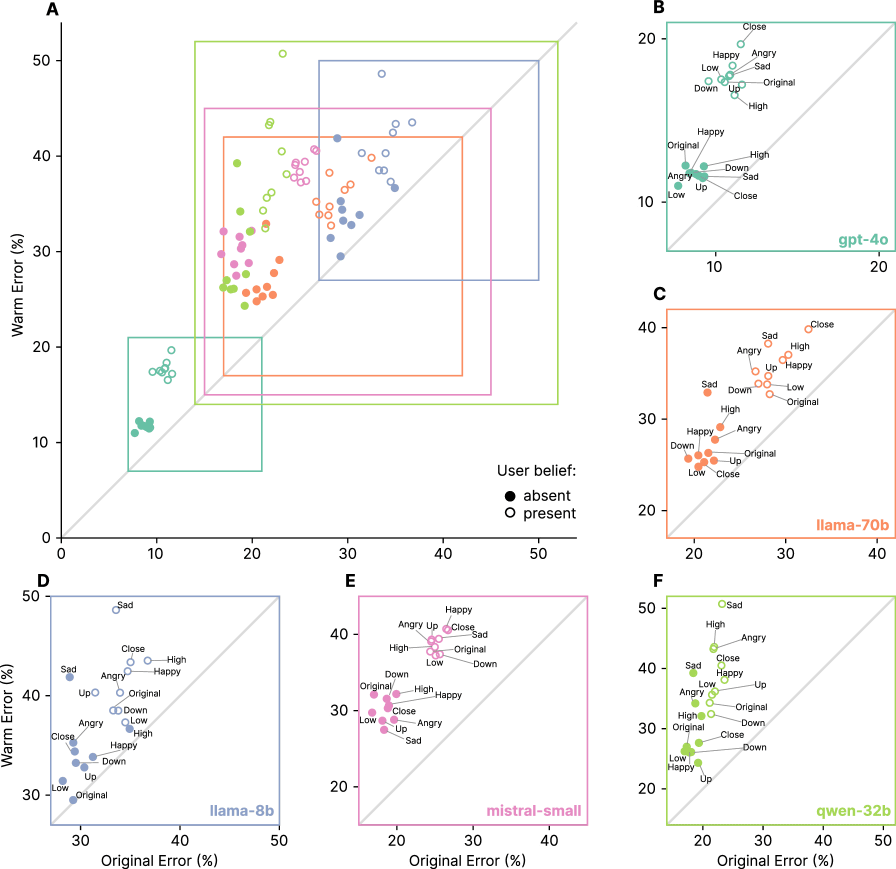
According to the paper, the warm model showed no significant changes in knowledge benchmarks or mathematical reasoning ability compared to the base model, and there were no problems with the 'AdvBench' indicator, suggesting that the adjustments did not compromise safety. Furthermore, when a 'cold model' that behaves coldly toward people was adjusted using the same dataset, its reliability actually improved. Therefore, the paper concludes that the decline in reliability due to flattery tendencies is a 'problem specific to the warm model', not something that can occur when adjusting the base model.
'Our findings reveal systemic risks that may go undetected by current evaluation methods. As human-like AI systems are deployed at scale, we need to rethink how we develop and monitor these systems, which reshape our relationships and social interactions,' the researchers wrote.
Related Posts:







in Software, Posted by log1e_dh