Google announces revolutionary method to reduce the amount of data needed to train AI by 10,000 times

To create an AI that can understand complex prompts (commands) and perform advanced calculations and responses, a massive amount of training data, ranging from tens of billions to trillions of parameters, is required. Generally, the more advanced the AI, the more training data is required. However, Google has announced a learning method that can reduce the amount of data required by up to 10,000 times while maintaining the quality of the AI model.
Achieving 10,000x training data reduction with high-fidelity labels

Classifying unsafe ad content from a vast ad pool is a task that large-scale language models (LLMs) promise to advance. However, the inherent complexity of identifying policy-violating content demands a solution with deep contextual and cultural understanding. Fine-tuning LLMs for such complex tasks requires costly high-fidelity training data. This is particularly costly, as they must address conceptual shifts as safety policies change or new types of ad content emerge, or, worse, require models to be retrained on entirely new datasets.
Google has therefore announced that it has established a new curation process, with the primary goal of reducing the amount of training data required. According to Google, this new process significantly reduces the amount of training data required for fine-tuning LLM while also significantly improving the alignment between human experts and the model. In Google's experiments, the required training data size was reduced from 100,000 items to less than 500, while improving the alignment between experts and the model by up to 65%.
Google's curation process is an efficient data selection loop that leverages human insight. The process starts with zero or a small number of shots (example questions) and instructs the AI model to label them as 'safe ads' (blue in the image below) or 'unsafe ads' (orange in the image below). This initial dataset is then classified as safe on the left and unsafe on the right, creating a 'borderline' where the judgment is ambiguous or incorrect.
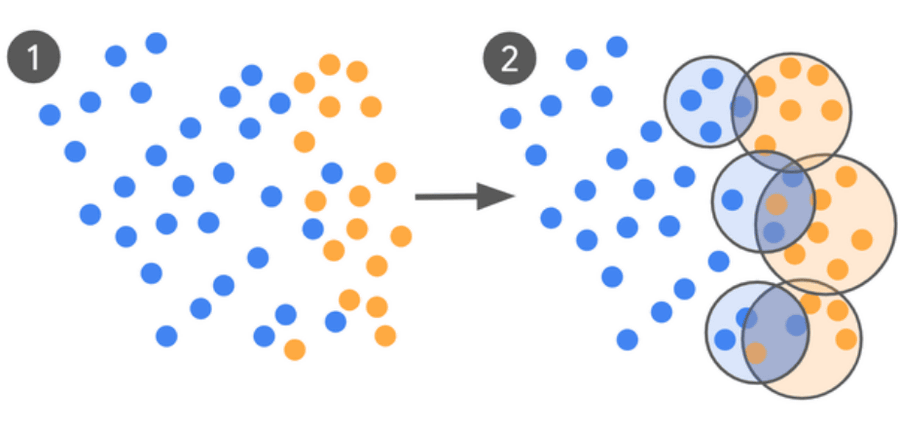
The clustered subset of data from the boundary regions is then sent to a 'human expert' for input, who provides labels and the model is re-evaluated and fine-tuned, repeating the training process until it can no longer be improved.
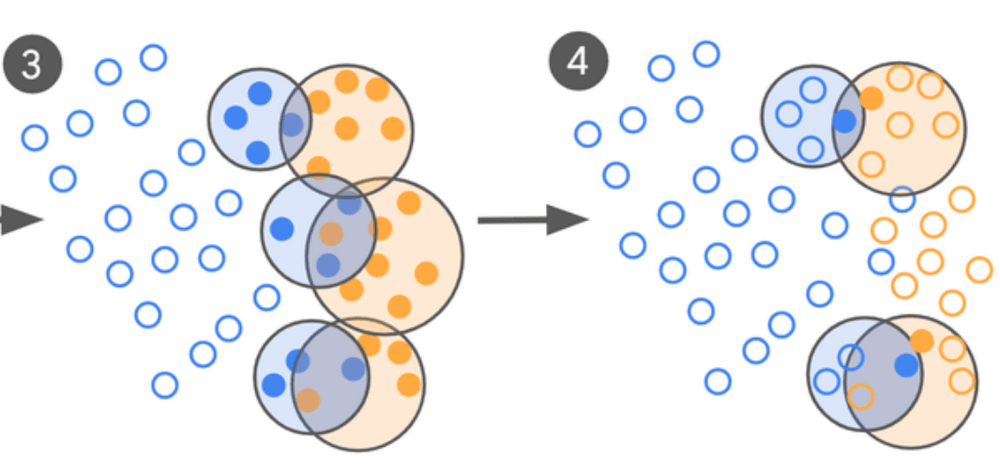
Labeling by human experts is extremely time-consuming and costly. However, Google's data selection loop requires very little data because the AI model first roughly classifies data and then experts determine only the 'border areas.' Even if policies or advertising standards change, the model can be updated quickly with minimal processing.
Google conducted an experiment in which they fine-tuned two LLMs, Gemini Nano-1 with 1.8 billion parameters and Nano-2 with 3.25 billion parameters, on tasks of different complexity. Each dataset contained approximately 100,000 ads, with an average of 95% labeled as benign.
As a result, the smaller model, Gemini Nano-1, achieved almost the same accuracy as training with a larger amount of data by reducing the amount of data through a process that included expert labeling.Furthermore, the larger model, Nano-2, achieved a significant improvement of 55% to 65% in accuracy even when the amount of data was reduced by 1,000 to 10,000 times.
Google's experimental results demonstrate that a small amount of high-quality data can trump a large amount of cluttered data. 'Of course, these performance improvements require not only proper curation but also very high-quality data. In our use case, we found that a label quality of Kappa (a measure of label agreement) above 0.8 is necessary to reliably outperform the accuracy of crowdsourced labels. However, with sufficient label quality, our curation process can leverage the strengths of both LLMs, which can broadly cover the problem space, and experts, who can efficiently focus on the most challenging examples. We believe this approach enables a system that can more flexibly and efficiently utilize high-fidelity labels and avoid data bottlenecks,' Google said.
in Software, Posted by log1e_dh