Xiaomi releases 'MiDashengLM,' an AI model with excellent voice understanding capabilities, as open source. A high-quality model developed based on the voice recognition technology used in Xiaomi EVs.

The Chinese company Xiaomi develops a wide range of products, including smartphones, PCs, and electric vehicles, and is also focusing on AI research. Xiaomi recently released a new voice recognition AI model, the MiDashengLM-7B , on Monday, August 4, 2025.
Xiaomi Development Voice Sound Understanding Large Model MiDashengLM-7B
GitHub - xiaomi-research/dasheng-lm: Efficient audio understanding with general audio captions
https://github.com/xiaomi-research/dasheng-lm
Xiaomi announced its voice recognition AI platform model ' Dasheng ' in 2024, which has been used in products such as electric vehicles and smart home devices. The newly released MiDashengLM-7B is a voice recognition AI model developed based on Dasheng and ' Qwen2.5-Omni ,' and is capable of highly accurate recognition of information such as the source of the voice, the environment in which the voice was recorded, and the language contained in the voice.
The following chart compares the benchmark scores of the MiDasheng LM-7B (blue), the Qwen2.5-Omni-7B (red), and the Kimi-Audio-Instruct-7B (yellow). The MiDasheng LM-7B achieved the highest scores in most tests.
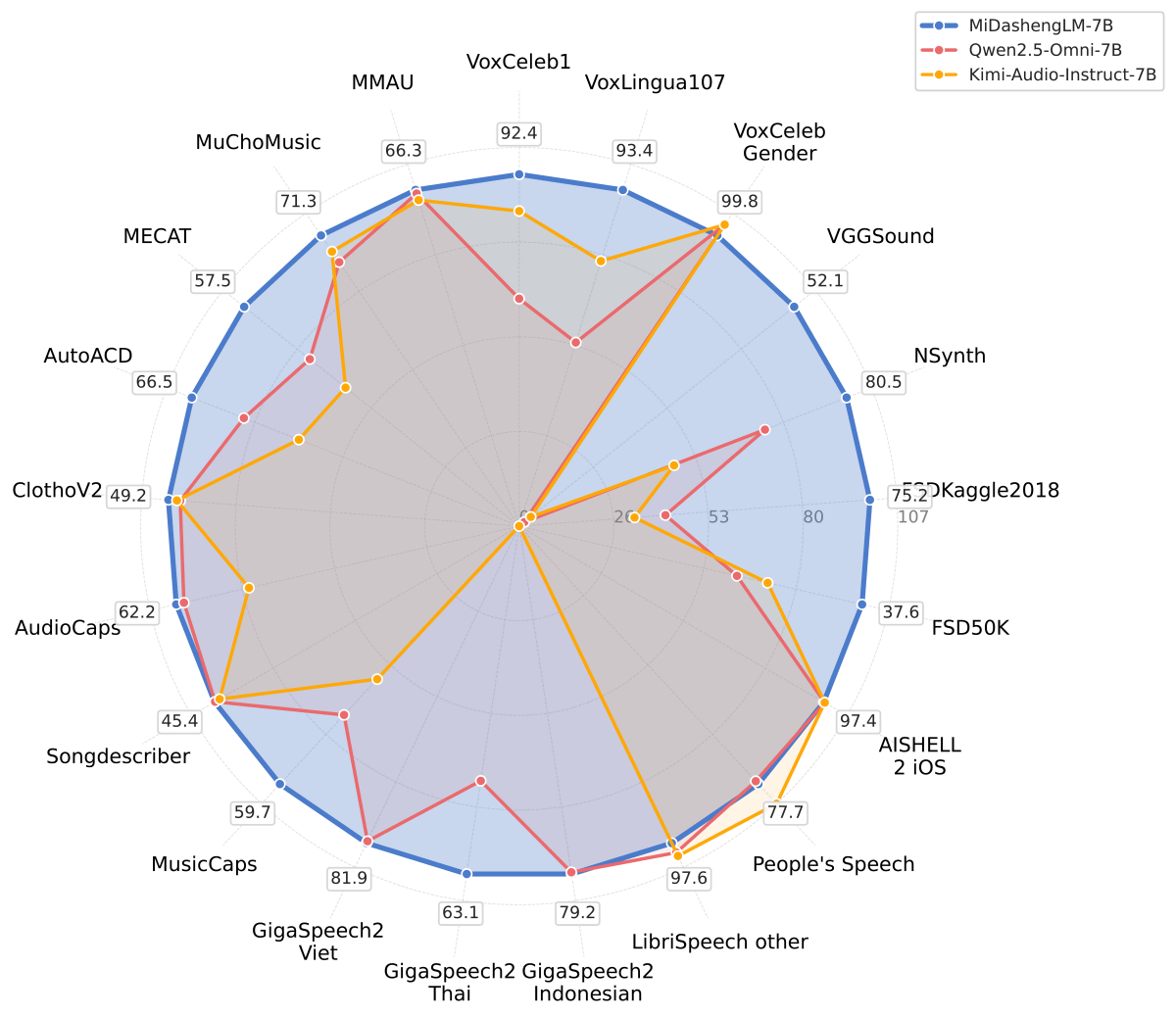
On

In addition, the MiDashengLM-7B was also able to recognize environmental sounds more accurately, such as the sound of a coin falling and the sound of water droplets falling.

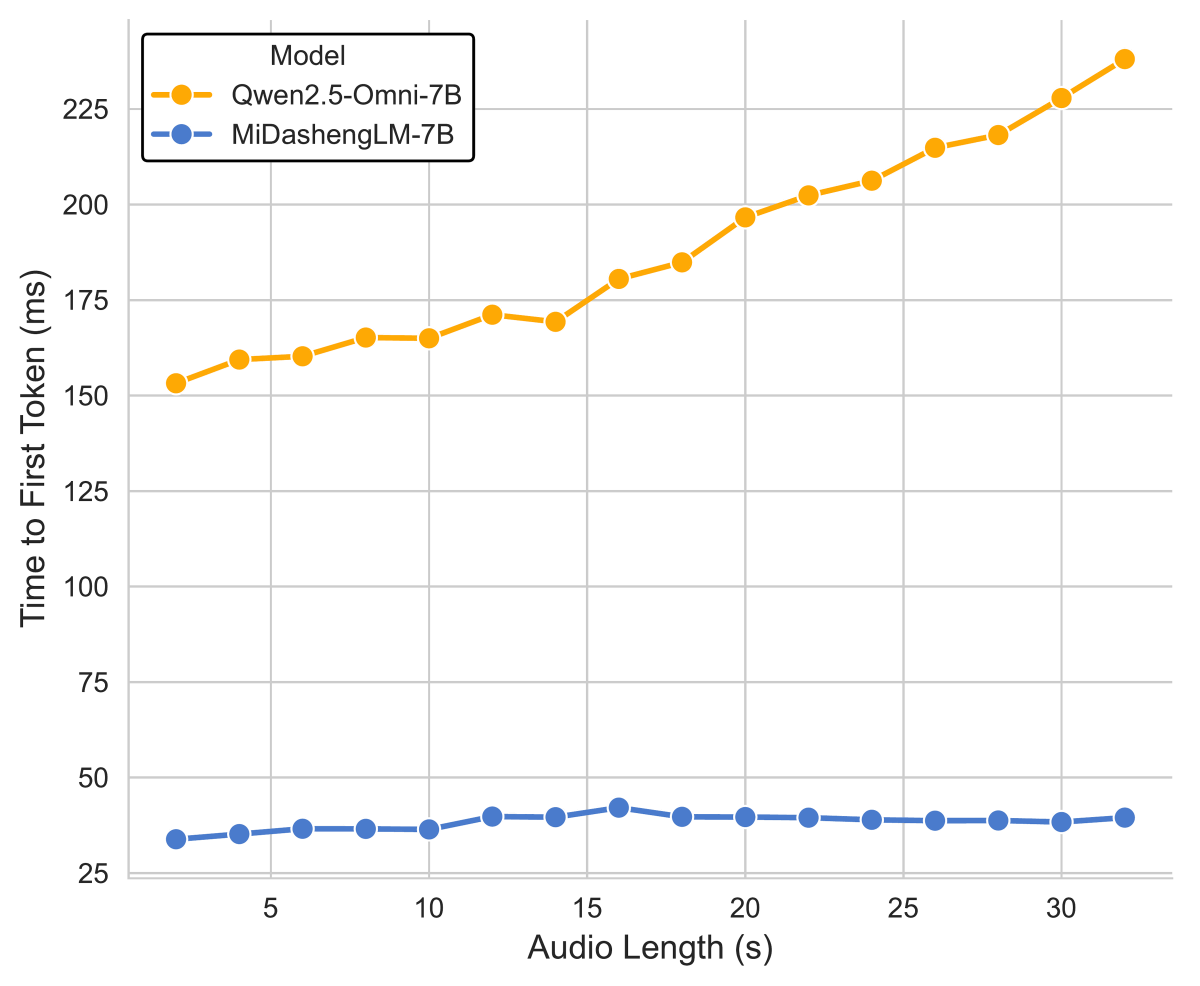
One of the features of the MiDashengLM-7B is its fast response time. The graph below compares the response time of the MiDashengLM-7B (blue) and the Qwen2.5-Omni-7B (yellow), with the horizontal axis representing the length of the input audio and the vertical axis representing the time it took to reach the first output. The MiDashengLM-7B has a faster response time than the Qwen2.5-Omni-7B, and is able to maintain its response time even when the input audio is longer. Processing speed can also be increased by increasing the number of batches.
While speech recognition AI is often trained with audio data and a transcript of the audio, the MiDashengLM-7B is trained with audio data and a text description of the audio. This allows it to understand music and the speaker's emotions, which are difficult for conventional speech recognition AI to do.
The MiDashengLM-7B model data is available at the following link. The ACAVCaps dataset, created for the development of the MiDashengLM-7B, will also be released after the audit is complete.
mispeech/midashenglm-7b · Hugging Face
https://huggingface.co/mispeech/midashenglm-7b
Related Posts:






in Software, Posted by log1o_hf