The open source AI model 'Qwen3-235B-A22B-Thinking-2507' has been released and outperforms OpenAI and Google's AI models in major benchmarks
The '
Qwen3-235B-A22B-Thinking-2507
https://simonwillison.net/2025/Jul/25/qwen3-235b-a22b-thinking-2507/
It's Qwen's summer: Qwen3-235B-A22B-Thinking-2507 tops charts | VentureBeat
https://venturebeat.com/ai/its-qwens-summer-new-open-source-qwen3-235b-a22b-thinking-2507-tops-openai-gemini-reasoning-models-on-key-benchmarks/
Alibaba announced the Qwen3 family at the end of April 2025. The flagship model, Qwen3-235B-A22B, has 235 billion parameters and 22 billion active parameters, and has achieved competitive results in benchmark evaluations of coding, mathematics, general functions, and other cutting-edge AI models from other companies, such as DeepSeek-R1, o1, o3-mini, Grok-3, and Gemini-2.5-Pro.
Alibaba announces 'Qwen3', an inference model with higher performance than GPT-4o and o1, and the flagship model 'Qwen3-235B-A22B' has 235 billion parameters and 22 billion active parameters - GIGAZINE

The 'Qwen3-235B-A22B-Thinking-2507' is an improved version of the 'Qwen3-235B-A22B'. Compared to 'Qwen3-235B-A22B', 'Qwen3-235B-A22B-Thinking-2507' has significantly improved performance in reasoning tasks, including academic benchmarks that require human expertise in logical reasoning, mathematics, science, coding, and general functions, and has achieved the best performance among open source reasoning models. However, due to the improved reasoning ability, 'Qwen3-235B-A22B-Thinking-2507' has a longer thinking time, so it is recommended to use it for complex reasoning tasks.
🚀 We're excited to introduce Qwen3-235B-A22B-Thinking-2507 — our most advanced reasoning model yet!
— Qwen (@Alibaba_Qwen) July 25, 2025
Over the past 3 months, we've significantly scaled and enhanced the thinking capability of Qwen3, achieving:
✅ Improved performance in logical reasoning, math, science & coding… pic.twitter.com/vO6UHlW7pf
Below are multiple benchmark tests comparing the inference models 'Qwen3-235B-A22B-Thinking-2507' (red), 'Qwen3-235B-A22B-Thinking' (blue), 'Gemini 2.5 Pro' (gray), 'OpenAI o4 mini' (dark brown), and 'DeepSeek R1 0528' (light brown). Benchmark tests related to biology, physics, and chemistry are GPQA , benchmark tests related to mathematics are AIME25 , benchmark tests related to coding are LiveCodeBench v6 , and benchmark tests related to inference ability and advanced expertise are HLE .
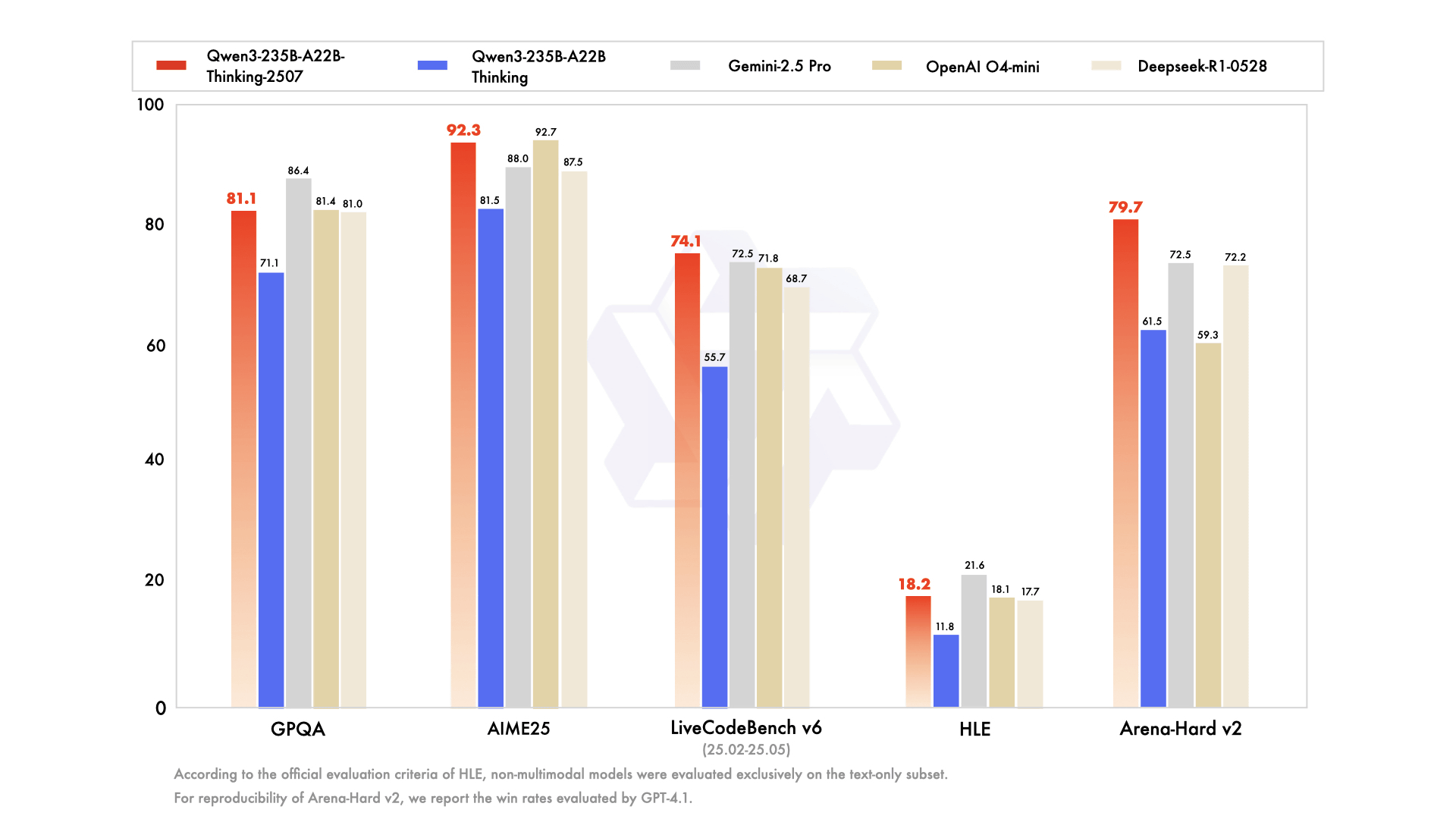
Regarding the results of the benchmark test of 'Qwen3-235B-A22B-Thinking-2507', David Hendrickson, a software engineer at Columbia University, said, 'The wins from China are just coming. They are the winners of open source language models now. This new model, Qwen3-235B-A22B-Thinking-2507, is the most high-performance open source inference model. It is a model with a context length of 130,000, and it outperforms the o1, o3-mini, Opus4, and Flash 2.5, which have a context length of 120,000, in
The wins keep coming out of China. They are now the champions of Open-Source language models. This new model, Qwen3-235B-A22B-Thinking-2507, is the most performant open-source thinking model. w/130K context it even beats O1, O3-mini, Opus4, Flash 2.5 @ 120K context in LiveBench https://t.co/jpouEiBy4s pic.twitter.com/sMHl7tV8JC
— David Hendrickson (@TeksEdge) July 25, 2025
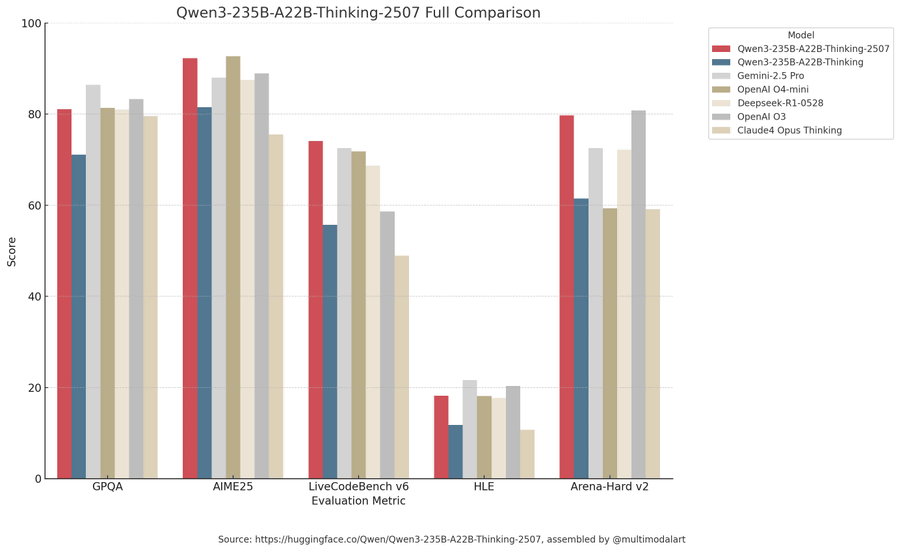
The graph comparing the benchmark results published by Alibaba did not include the benchmark results of Claude Opus 4 Thinking (brown) and OpenAI o3 (dark gray), so Apolinario created a graph comparing them.
Simon Willison, an engineer who runs a unique AI benchmark called '
'Qwen3-235B-A22B-Thinking-2507' is available on Alibaba Cloud.
Try it via API: Qwen3-235B-A22B-Thinking-2507 is now available on Alibaba Cloud! pic.twitter.com/W7so04P6Ut
— Qwen (@Alibaba_Qwen) July 25, 2025
It is also published on Hugging Face.
Qwen/Qwen3-235B-A22B-Thinking-2507 · Hugging Face
https://huggingface.co/Qwen/Qwen3-235B-A22B-Thinking-2507
Related Posts:





in Software, Posted by logu_ii