A web app that can quickly calculate whether your graphics card can run AI based on VRAM capacity.
To run an AI model, you need a graphics board with sufficient VRAM capacity or an AI processing chip. The free web application 'LLM Inference: VRAM & Performance Calculator' registers the VRAM capacity of various devices and the VRAM usage of AI models, so you can quickly calculate 'Can I run AI in my environment?' and 'What kind of environment do I need to prepare to run any AI model?'.
Can You Run This LLM? VRAM Calculator (Nvidia GPU and Apple Silicon)
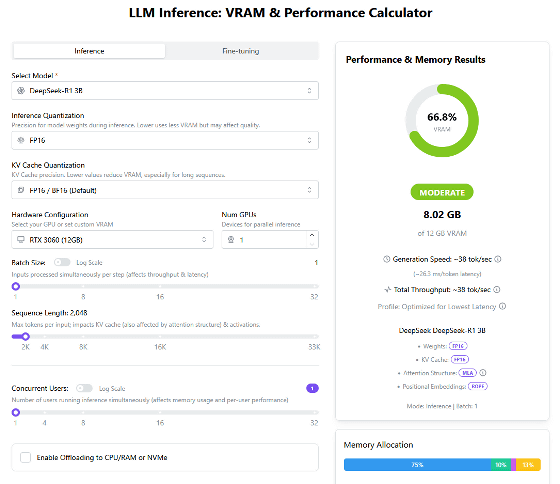
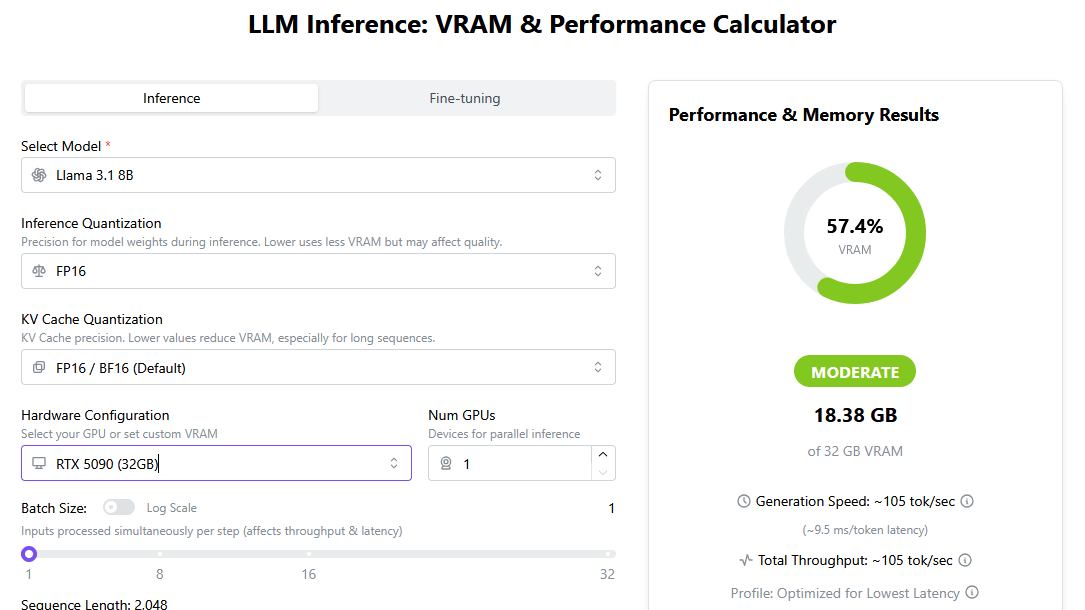
In 'LLM Inference: VRAM & Performance Calculator', you can specify the AI model and device to be used, and check whether the AI model can be executed based on the VRAM capacity. Select the AI model from the selection box at the top left of the screen, and the device from the selection box in the middle of the screen. When you select the AI model and device, the VRAM consumption of the AI model and the VRAM usage of the device are displayed on the left side of the screen. In the initial state, the AI model is selected as 'DeepSeek-R1 3B' and the device is selected as 'RTX 3060 (12GB)', and you can see that the VRAM usage is 66.8% and can be executed without any problems.
Changed the AI model to 'Llama 3.1 8B'.
'Llama 3.1 8B' requires 18.38GB or more of VRAM, but the 'RTX 3060 (12GB)' only has 12GB of VRAM, so it cannot run on the system.
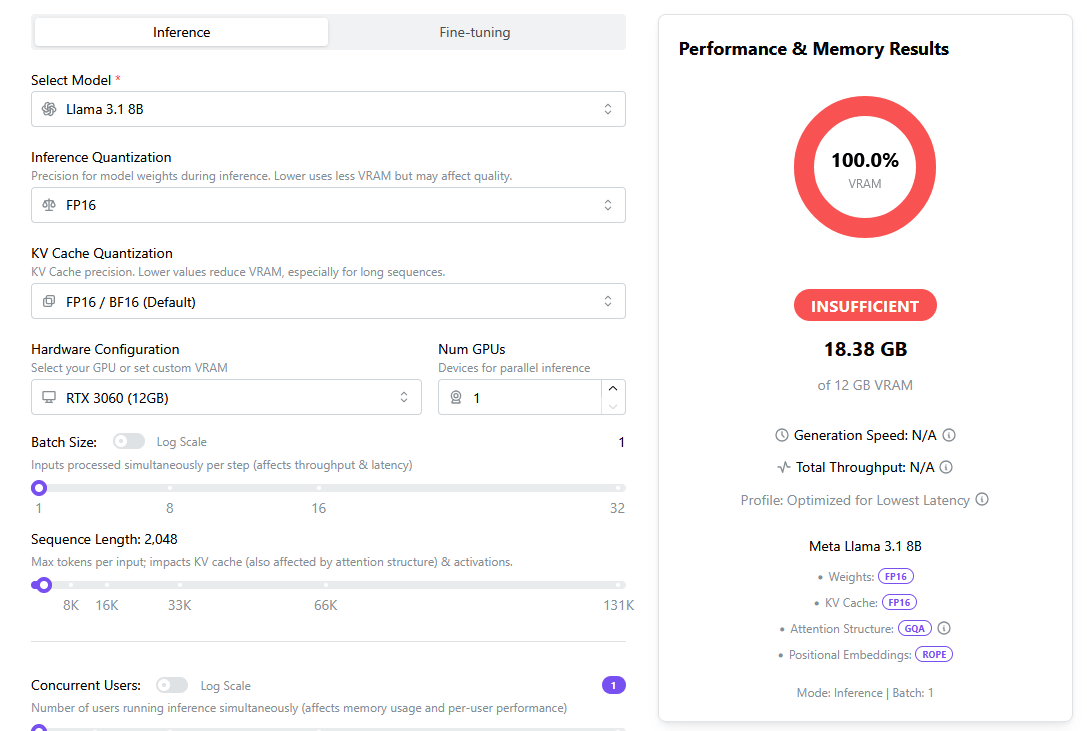
Change the device to 'RTX 5090 (32GB)'.
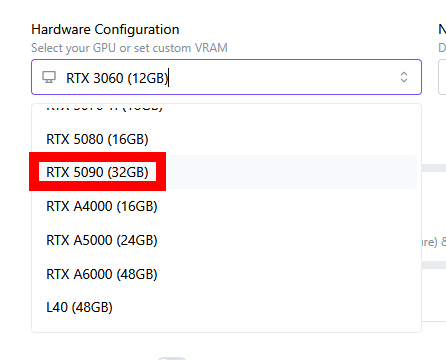
The RTX 5090 (32GB) can run Llama 3.1 8B on its own.
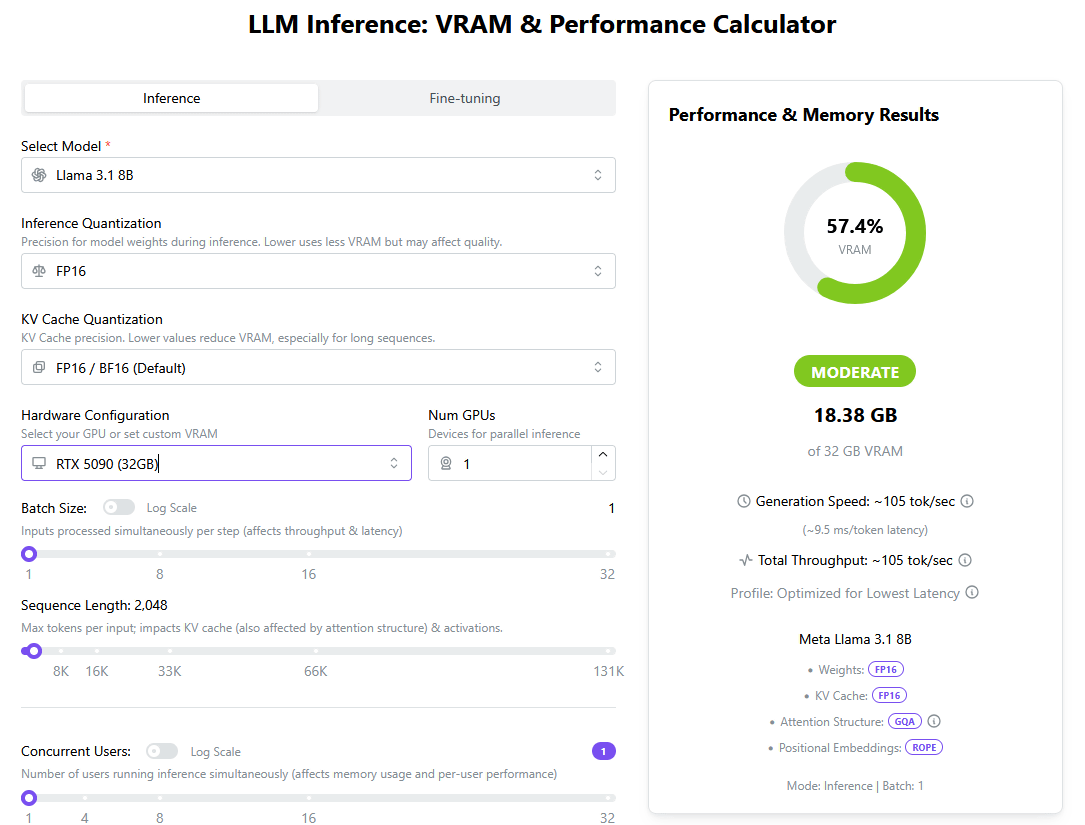
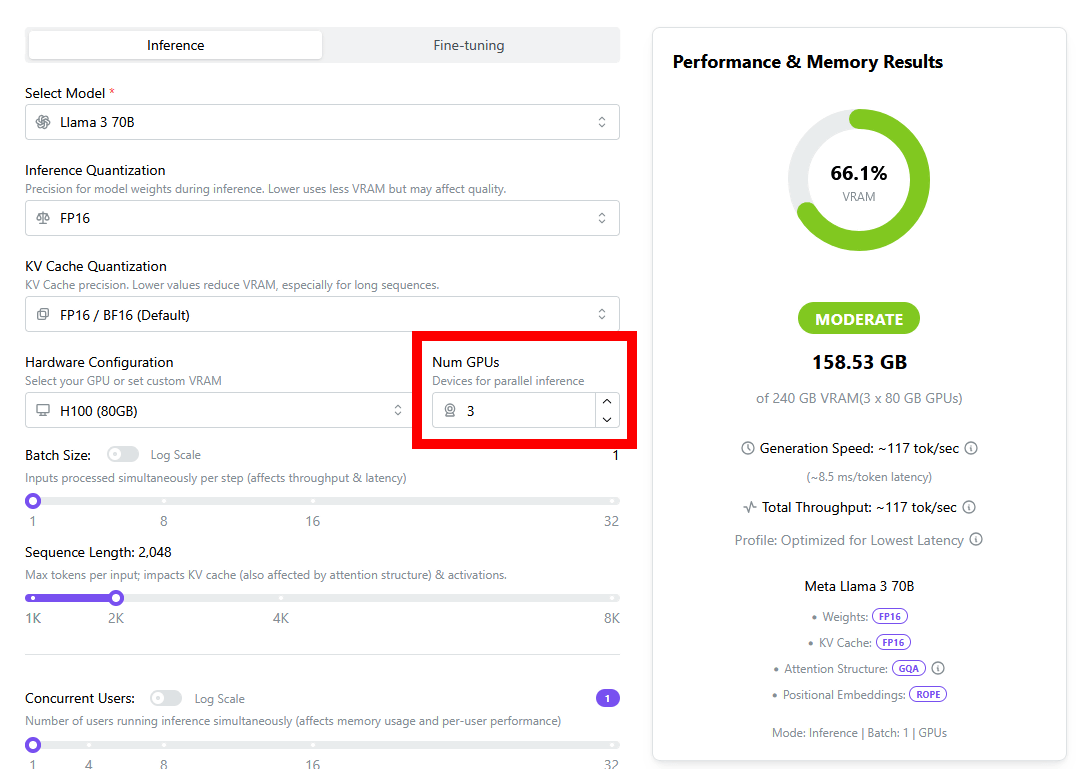
'LLaMA Inference: VRAM & Performance Calculator' can also simulate data center devices such as H100 and H200. When we set the AI model to 'LLaMA 3 70B' and the device to 'H100 (80GB)', we found that one 'H100 (80GB)' could not run 'LLaMA 3 70B'.
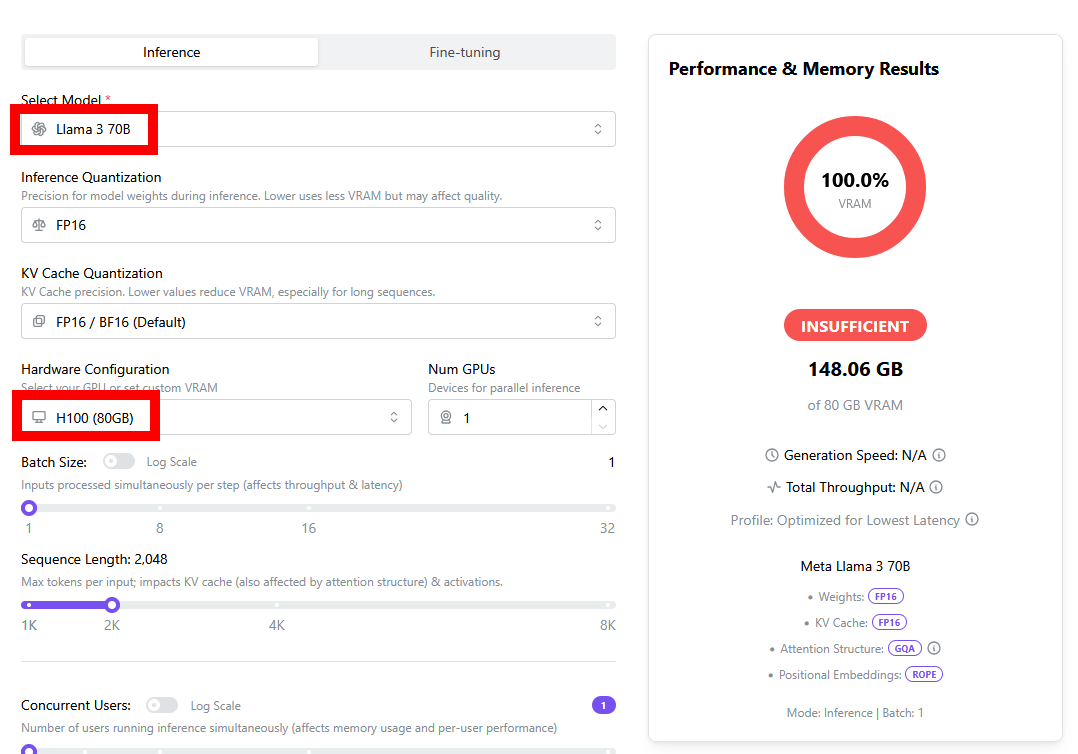
To the right of the device selection field is a field for selecting the number of devices, which allows you to calculate the results when devices are operated in parallel. By increasing the number of 'H100 (80GB)' devices by one, we found that 'LLaMA 3 70B' could be run in parallel on three devices.
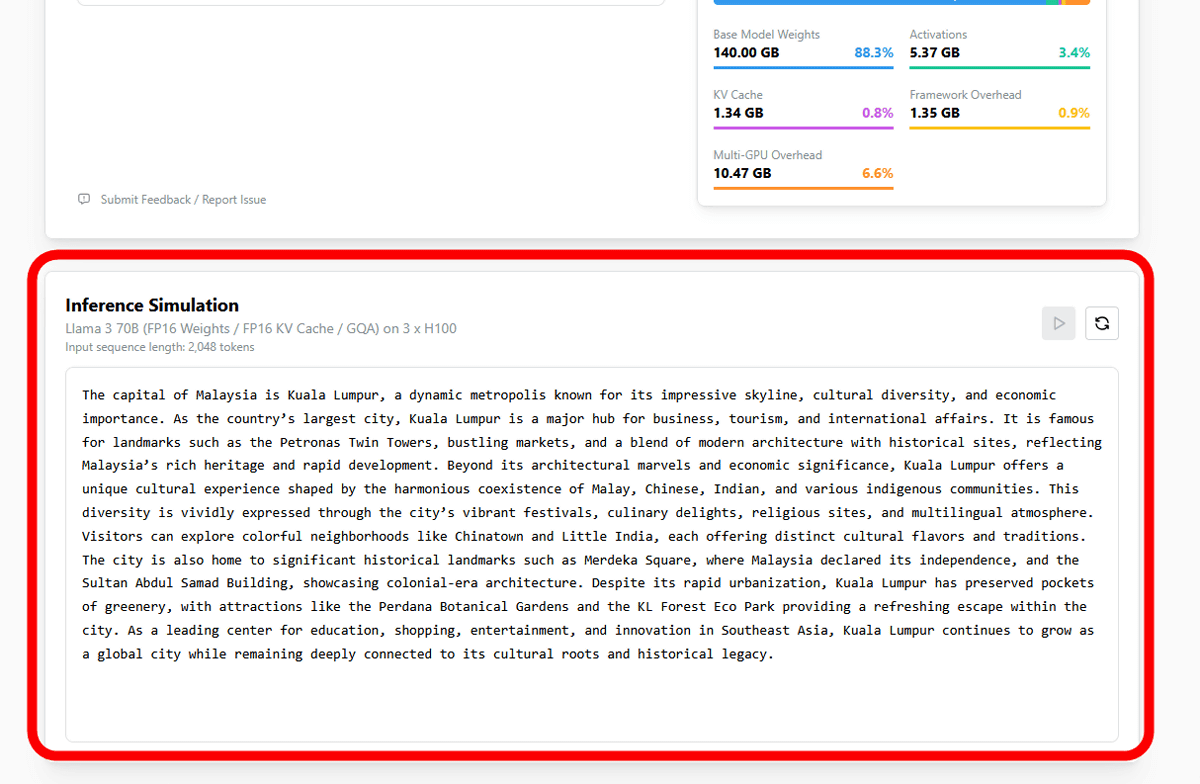
In addition, the bottom of the 'LLM Inference: VRAM & Performance Calculator' screen also provides a demo of the token processing speed of the AI model, allowing you to simulate the text output speed for the selected combination of AI model and device.
in Software, Web Application, Hardware, Posted by log1o_hf