Apple unveils its proprietary visual language model 'FastVLM' that achieves high levels of accuracy and efficiency, ideal for on-device real-time visual query processing
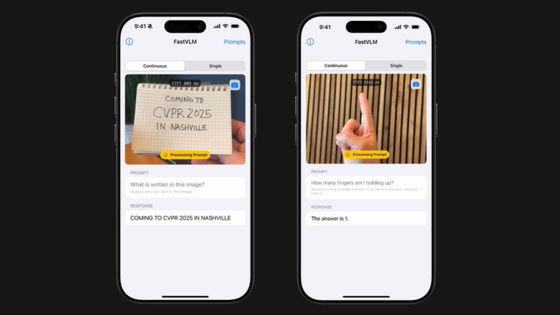
Apple has announced its own visual language model (VLM), ' FastVLM '. Conventional VLMs have the problem of decreasing efficiency as their accuracy increases, but FastVLM maintains high accuracy while also demonstrating excellent performance in terms of efficiency, making it an AI model suitable for on-device real-time visual query processing.
FastVLM: Efficient Vision Encoding for Vision Language Models - Apple Machine Learning Research
GitHub - apple/ml-fastvlm: This repository contains the official implementation of 'FastVLM: Efficient Vision Encoding for Vision Language Models' - CVPR 2025
https://github.com/apple/ml-fastvlm
A visual language model (VLM) is an AI model that allows visual understanding in addition to text input. VLMs are typically constructed by passing visual tokens from a pre-trained vision encoder through a projection layer to a pre-trained large-scale language model (LLM). By leveraging the rich visual representation of the vision encoder and the world knowledge and reasoning capabilities of the LLM, VLMs can be used in a wide range of applications, including accessible assistants, UI navigation, robotics, and games.
Since the accuracy of VLMs generally improves with higher resolution input images, there is a trade-off between accuracy and efficiency, especially for tasks that require detailed understanding, such as document analysis, UI recognition, and answering natural language queries about images. For example, if you ask a VLM about a road sign shown in an image, it will not respond correctly if the input image is low-resolution, but it will be able to correctly identify the sign if the input image is high-resolution.
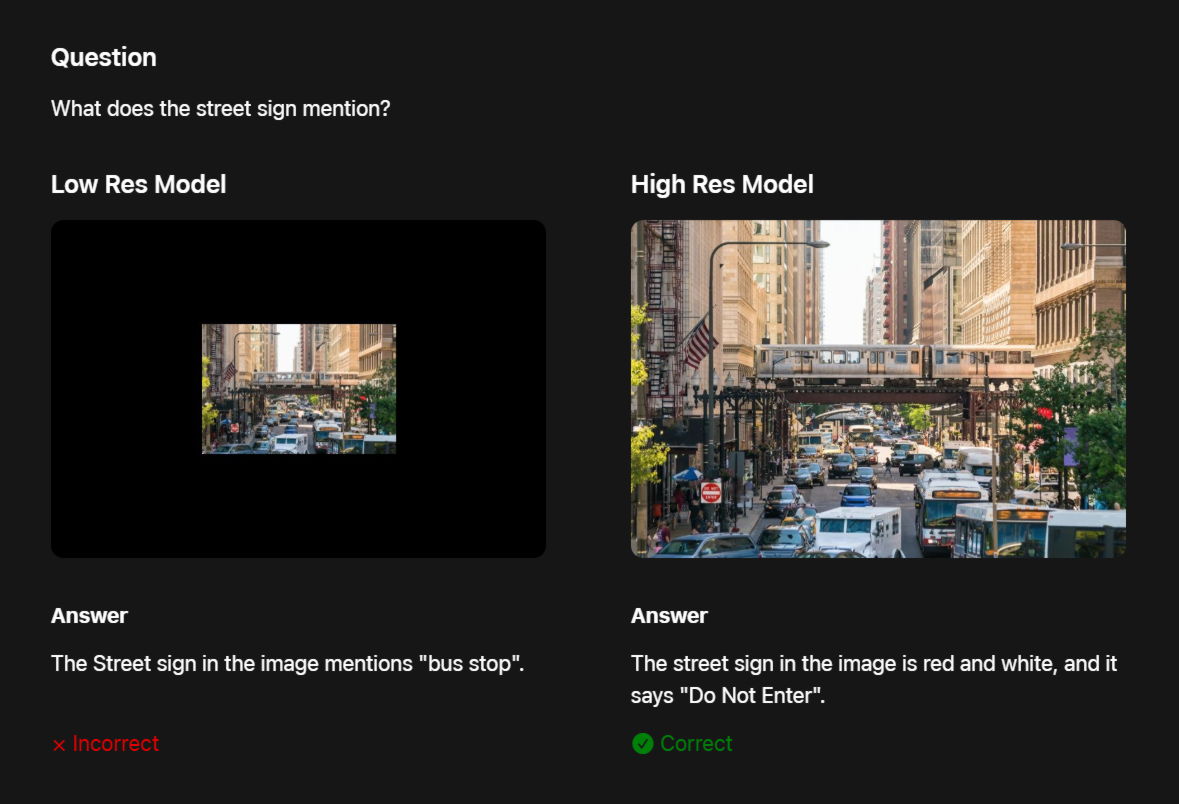
Meanwhile, in many production use cases, VLM not only needs to run on-device, but also needs to be both accurate and efficient to meet the low latency requirements of real-time applications and enable privacy-preserving AI experiences.
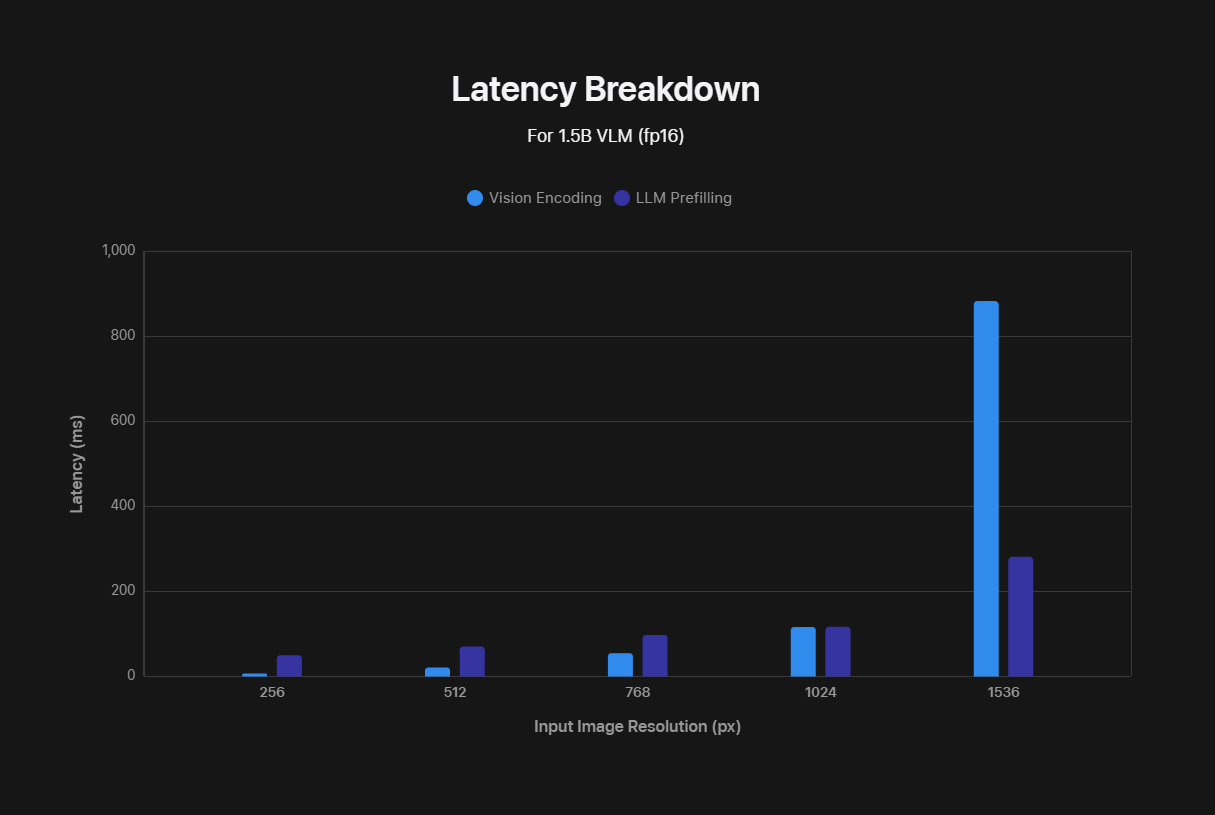
However, high-resolution images significantly increase the latency of VLM, which means it is less efficient. The efficiency loss occurs in two ways. First, high-resolution images require more processing time for the vision encoder. Second, the encoder creates more visual tokens, which increases the pre-filling time for LLM. These factors increase
The following figure shows that as image resolution increases, both the vision encoding time and the LLM pre-input time increase. The horizontal axis is the input image resolution, and the vertical axis is the latency.
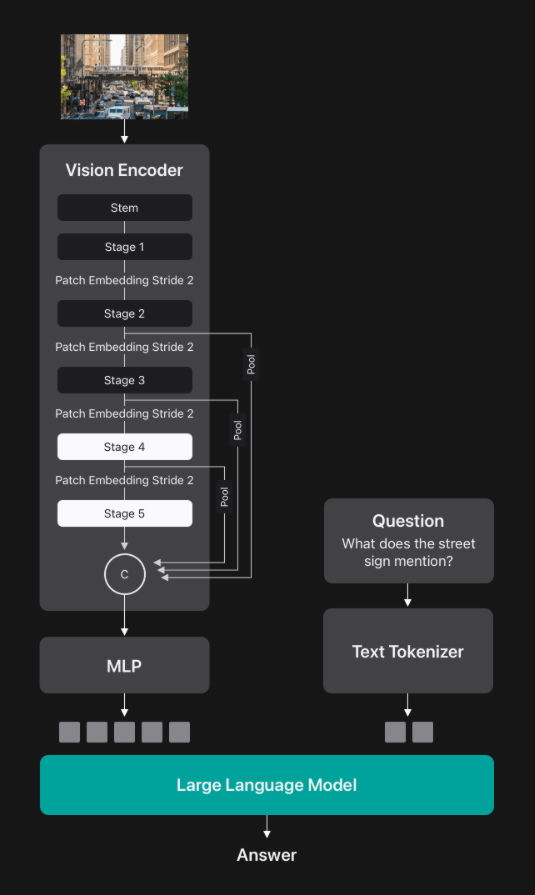
Apple's machine learning researchers have announced 'FastVLM,' which uniquely addresses the challenges of VLM. FastVLM is a VLM that has succeeded in significantly improving the trade-off between accuracy and latency with a simple design. It utilizes a hybrid architecture visual encoder designed for high-resolution images, which not only achieves accurate, fast and efficient visual query processing, but is also suitable for developing real-time applications that run on devices.
To determine which architecture offers the best accuracy-latency tradeoff, Apple first systematically compared the vision encoders while keeping everything the same: training data, recipes, LLMs, etc. The architectures studied included
FastViT is the best choice for efficient VLM, but it requires a larger vision encoder to improve accuracy on difficult tasks. Initially, Apple tried to simply scale up the size of each layer of FastViT, but this simple scaling made FastViT less efficient than a full convolutional encoder for high-resolution images. To address this issue, Apple designed a new backbone, FastViTHD, specifically for high-resolution images. FastViTHD has an additional stage compared to FastViT, and by pre-training using MobileCLIP , it can generate higher quality visual tokens with fewer numbers.
FastViTHD has better latency for high-resolution images than FastViT, but we also compare its performance when combined with LLMs of various sizes to evaluate which one is better for VLM. We evaluated different combinations of image resolution and LLM size, as well as three LLMs with different parameters, and combined them with vision backbones operating at different resolutions. The results show that FastViTHD can operate up to three times faster with the same accuracy.
FastVLM is a VLM that uses FastViTHD as a vision encoder and has a simple multi-layer perceptron (MLP) module that projects visual tokens into the embedding space of the LLM.
The following graph compares the performance and number of visual tokens required by FastVLM and other VLMs. The horizontal axis shows the number of visual tokens, and the vertical axis shows the average performance for various VLM tasks.
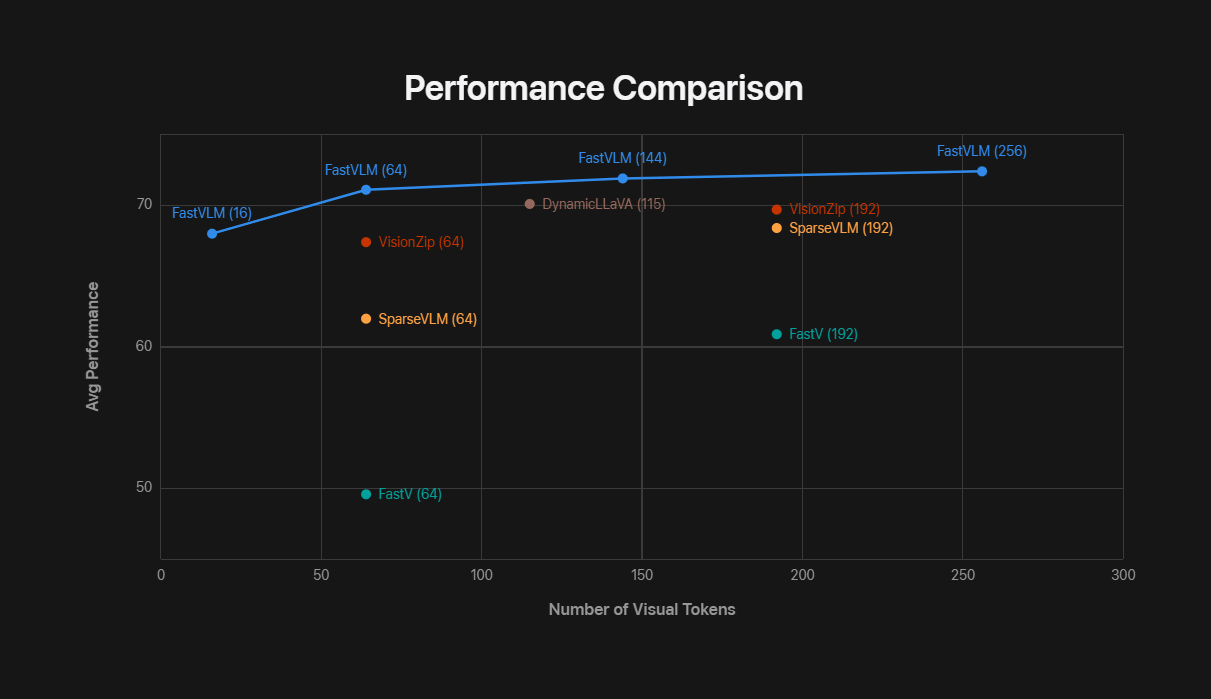
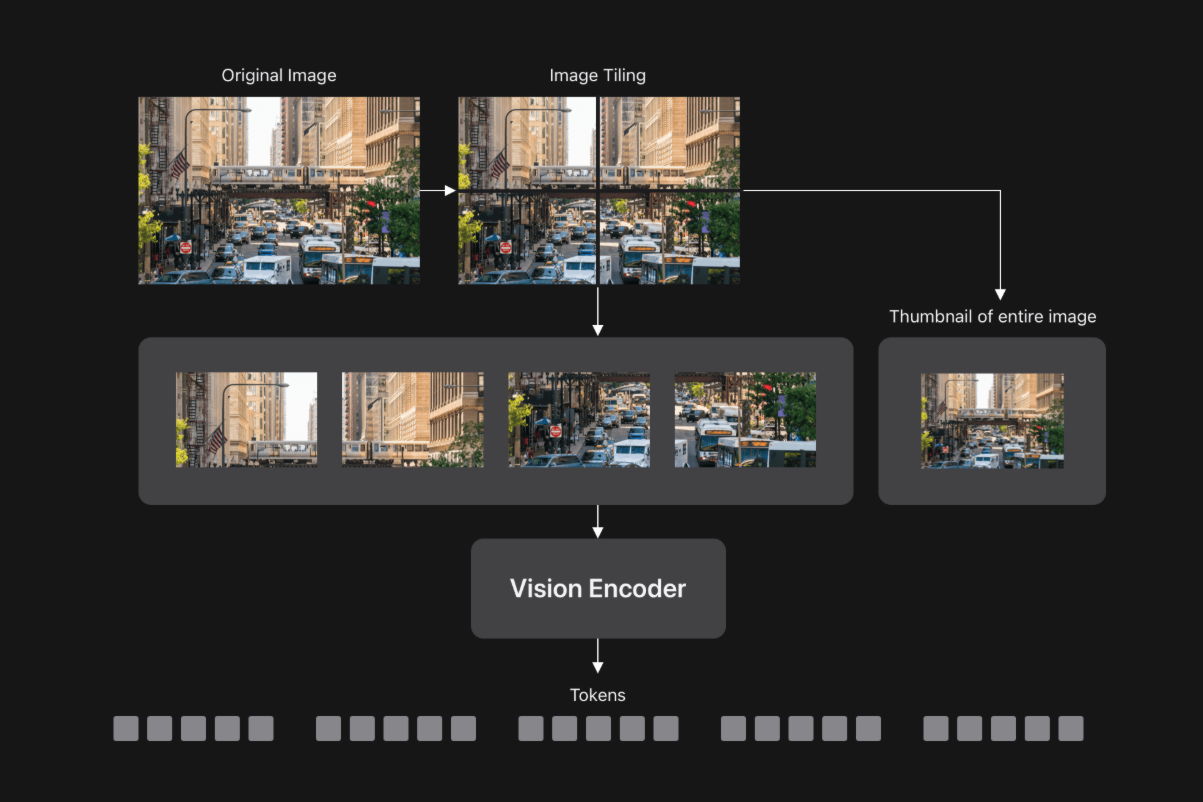
To process high-resolution images quickly, FastVLM divides the image into smaller pieces, processes each piece individually using a vision encoder, and then sends all tokens to the LLM.
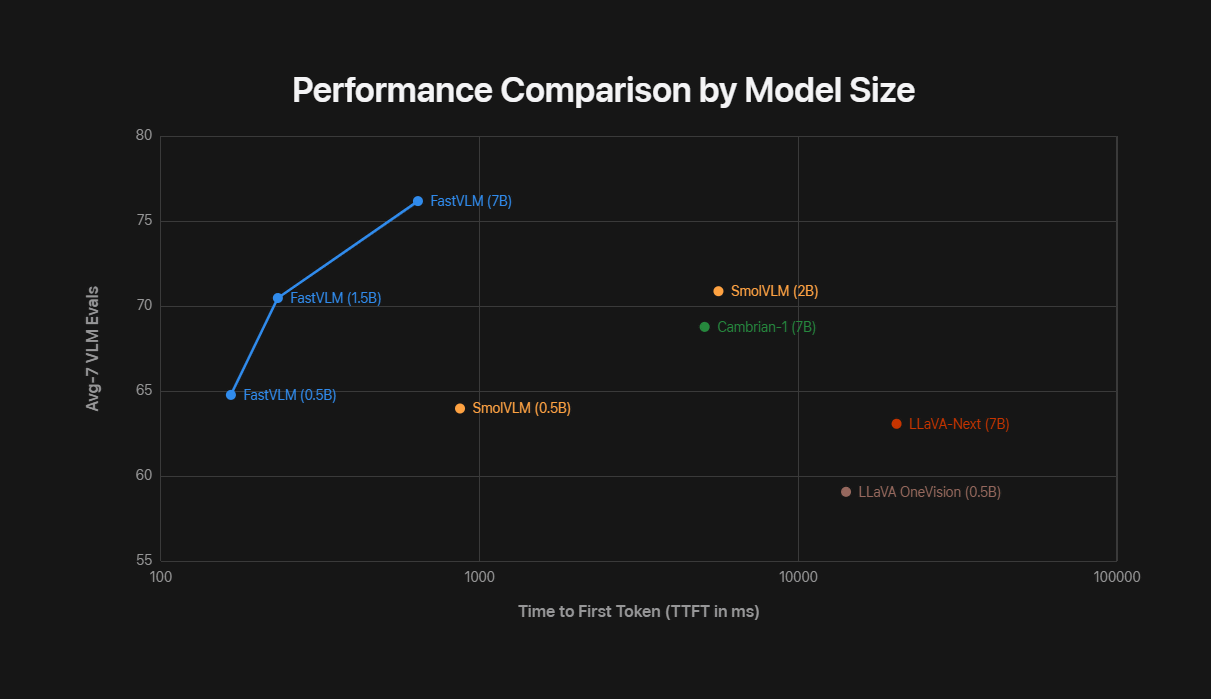
This allows FastVLM to operate faster and more accurately than a VLM of the same size. The graph below shows the average performance of seven VLM benchmarks, with the horizontal axis being the TTFT. FastVLM not only has high performance, but also has an overwhelmingly short TTFT, meaning it is highly efficient.
Below is an example of FastVLM running locally on an iPhone. We can see that it successfully recognizes the contents of the input image accurately in near real time.
VLM combines visual understanding and text understanding to realize a variety of applications. The accuracy of these models generally scales with the resolution of the input images, so there is often a performance trade-off between accuracy and efficiency, limiting the value of VLM in applications that require both high accuracy and good efficiency.
FastVLM addresses this trade-off by leveraging FastViTHD, a hybrid architecture vision encoder built for high-resolution images. Through its simple design, Apple claims that FastVLM outperforms traditional approaches in both accuracy and efficiency, enabling in-device visual query processing suitable for real-time in-device applications.
The inference code based on Apple'sMLX , model checkpoints, and the code for iOS and macOS demo apps are available on GitHub.
GitHub - apple/ml-fastvlm: This repository contains the official implementation of 'FastVLM: Efficient Vision Encoding for Vision Language Models' - CVPR 2025
https://github.com/apple/ml-fastvlm
Related Posts:








in Software, Posted by logu_ii