Mistral AI releases 'Voxtral', an open-source speech recognition model capable of transcription

French AI company Mistral AI has announced the release of its open voice recognition model, Voxtral . The company is promoting Voxtral as the first open model that can deploy 'voice intelligence that can actually be used in the field.'
Voxtral | Mistral AI
Mistral releases Voxtral, its first open source AI audio model | TechCrunch
https://techcrunch.com/2025/07/16/mistral-releases-voxtral-its-first-open-source-ai-audio-model/
Mistral AI said, 'Until now, developers have had to make a difficult choice between cheap open source systems with low transcription accuracy and insufficient contextual understanding, and closed APIs with high functionality but high cost and limited flexibility in deployment.' Mistral positions Voxtral as the first open model that can deploy 'true voice intelligence in production environments,' and says it solves this problem at an affordable price that is less than half the price of solutions with equivalent capabilities.
Voxtral offers two models depending on the application. One is 'Voxtral Small' with 24 billion parameters, which is intended for production-scale system deployment. This model is said to have performance that is competitive with models such as ElevenLabs' Scribe, GPT-4o-mini, and Gemini 2.5 Flash.
The other is the 3 billion parameter 'Voxtral Mini', a model suitable for use in local environments and edge devices. In addition, based on this Voxtral Mini, there is also a very inexpensive and fast API 'Voxtral Mini Transcribe' optimized specifically for transcription. Mistral AI appealed, 'Voxtral Mini has performance that exceeds that of OpenAI's Whisper at less than half the price.'
Below is a comparison of the cost performance of transcription for each model in terms of transcription error rate (vertical axis) and API usage price per minute (horizontal axis). Voxtral Small, Voxtral Mini, and Vox Mini Transcribe all show higher cost performance than GPT-4o mini, Gemini, and OpenAI's Whisper.
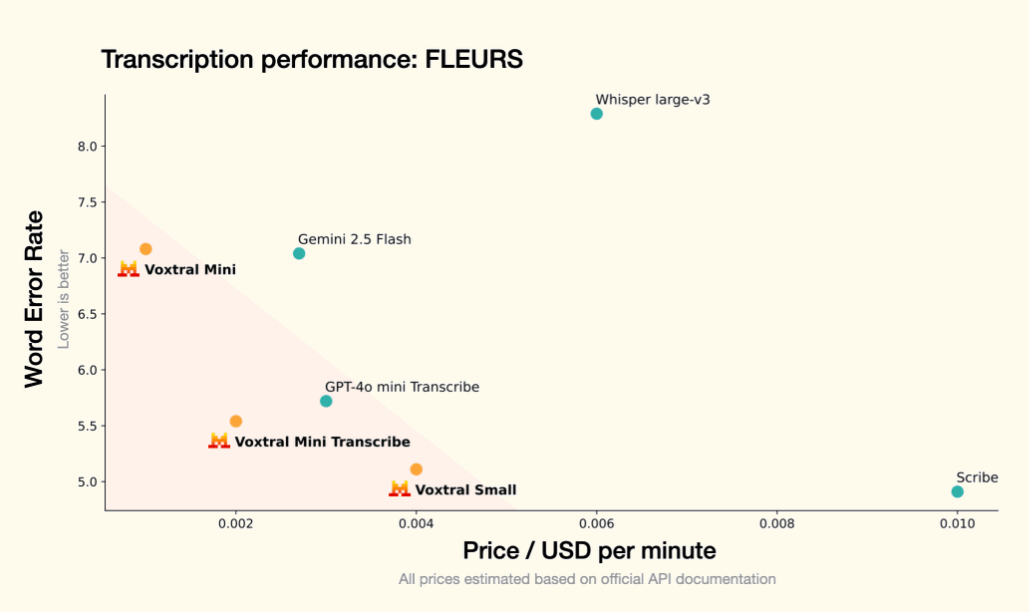
Below are the benchmark comparison results for English and other languages (
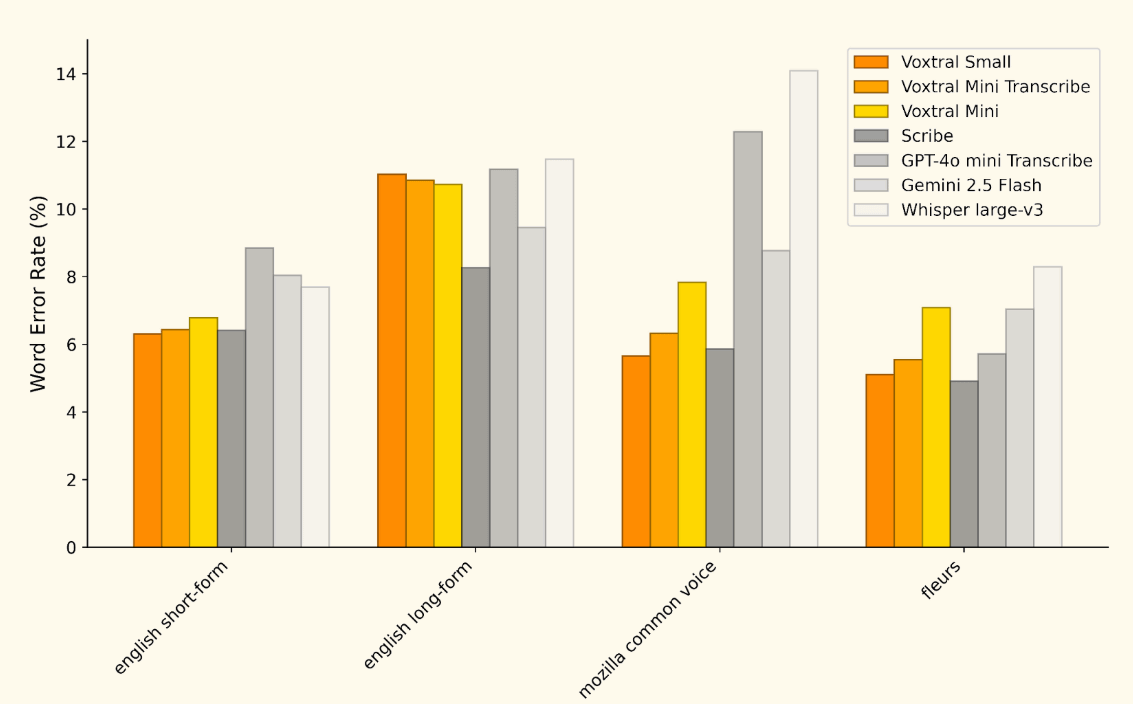
The results of comparing error rates in Italian, Spanish, English, German, Portuguese, French, Dutch, Hindi, and Arabic look like this.

In addition, Voxtral is based on the Mistral Small 3.1 LLM, which means that it can not only transcribe up to 30 minutes of audio, but also recognize up to 40 minutes of audio content. This allows users to directly ask questions about audio content, generate summaries, or convert voice commands into real-time actions such as API calls.
Voxtral is available in Italian, Spanish, English, German, Portuguese, French, Dutch, Hindi and Arabic. Voxtral models are hosted on Hugging Face and are released under the Apache 2.0 license.
mistralai (Mistral AI_)
https://huggingface.co/mistralai
Voxtral's API can be tried for free from Hugging Face, and can also be tested with Mistral's chatbot 'Le Chat'. API integration into applications is offered at an affordable price starting from $0.001 (approximately 0.15 yen) per minute. In addition, for businesses, on-premise deployment within their own infrastructure, fine-tuning for specific domains such as medicine and law, support for advanced functions such as speaker identification and emotion detection, and integration support into existing systems are also available. Mistral AI says it plans to add features such as speaker separation, word-level timestamps, and non-speech recognition in the future.
in Software, Posted by log1i_yk