Introducing 'Mercury,' a diffuse large-scale language model (dLLM) capable of Japanese language support and ultra-fast code generation

Introducing Mercury, our General Chat Diffusion Large Language Model
https://www.inceptionlabs.ai/introducing-mercury-our-general-chat-model
[2506.17298] Mercury: Ultra-Fast Language Models Based on Diffusion
https://arxiv.org/abs/2506.17298
Mercury: Ultra-Fast Language Models Based on Diffusion
https://arxiv.org/html/2506.17298v1
Inception Labs has announced Mercury, their next-generation dLLM, which is parameterized via the Transformer , a deep learning model developed by Google, and trained to predict multiple tokens in parallel.
Diffusion models have emerged as a state-of-the-art approach for generating images, enabling the production of consistently high quality and diverse content. The advantages of diffusion models over traditional autoregressive models are their parallel generation (i.e., faster processing speed) and their fine-grained control, inference, and multimodal data processing capabilities. However, scaling diffusion models to the scale of LLMs while maintaining high performance has been a major challenge.
In contrast, Mercury is a dLLM that achieves state-of-the-art performance and efficiency compared to comparable autoregressive models. Inception Labs describes Mercury as the 'first general-purpose chat model,' making it suitable for a wider range of text generation applications than ever before.
In addition, this Mercury is optimized for coding as 'Mercury Coder'. Inception Labs released Mercury Coder at the end of February 2025, and advertised that it can generate text up to 10 times faster than general AI models.
'Mercury Coder' is a diffusion-type language model that can extract words from noise and generate explosive code - GIGAZINE
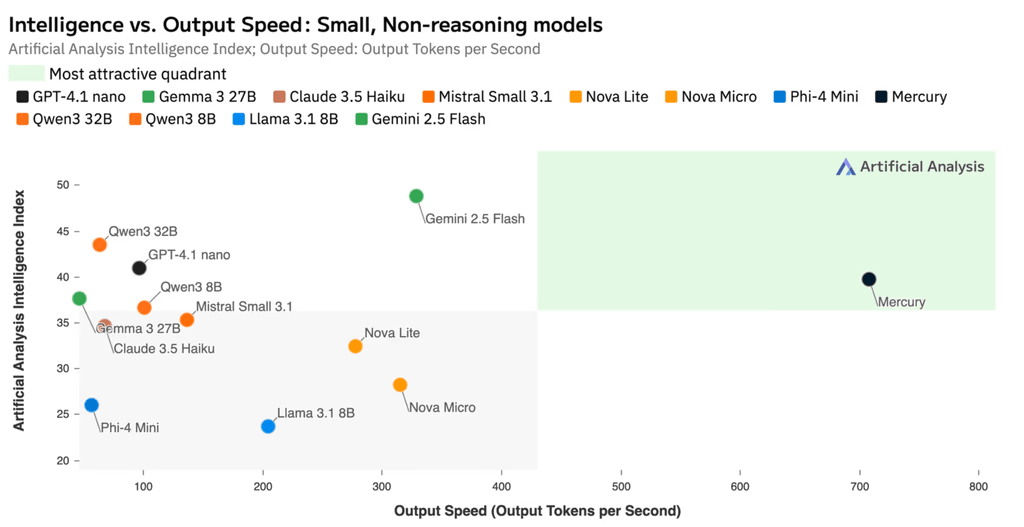
According to Artificial Analysis , which publishes comparative benchmarks of generative AI models, Mercury is more than seven times faster than lightweight models such as GPT-4.1 Nano and Claude 3.5 Haiku in terms of output speed.
The graph below compares the output quality (vertical axis) and output speed (horizontal axis) of each AI model. Mercury can output the same quality as lightweight models such as GPT-4.1 Nano and Claude 3.5 Haiku, but seven times faster.
'Mercury is the next step towards the diffusion-based future of language modeling, replacing the current generation of autoregressive models with extremely fast and powerful dLLMs,' Inception Labs said.
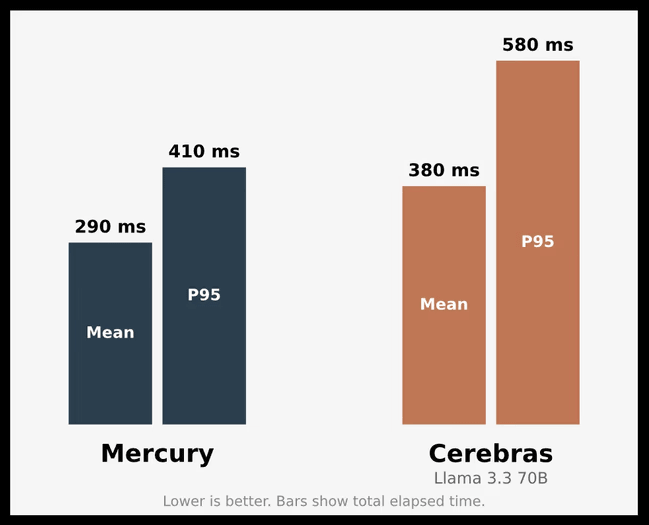
Mercury not only has a high output speed, but also has low latency. This makes it suitable for voice applications that require high responsiveness, from translation services to call center agents. The graph below shows the end-to-end latency of an actual voice agent prompt, compared to
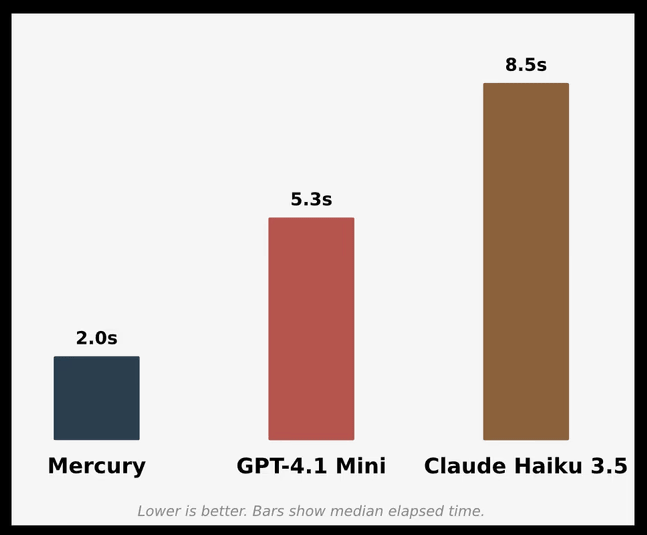
Microsoft has announced NLWeb , an open source tool that serves as the foundation for realizing conversational interfaces using natural language on the web. By combining this NLWeb with Mercury , it is possible to achieve ultra-fast, natural conversations based on real data. The graph below compares the program execution time when creating a conversational interface with Mercury, GPT-4.1 Mini, and Claude 3.5 Haiku. Mercury runs much faster than competing AI models while still providing a smooth user experience.
Mercury can be tried out on the Inception Labs demo site, as well as being available on OpenRouter and Poe .
Mercury Playground
https://chat.inceptionlabs.ai/

The fee for using Mercury is $0.25 (approximately 36.5 yen) per 1 million input tokens and approximately $1 (approximately 146 yen) per 1 million output tokens. However, the first 1,000 students and researchers will be able to use 10 million input tokens and 10 million output tokens for free.
Inception Platform
https://platform.inceptionlabs.ai/docs#models
Related Posts:







in Software, Posted by logu_ii