Researchers discover that Meta's AI 'Llama 3.1 70B' can reproduce 42% of the copyrighted 'Harry Potter and the Philosopher's Stone'

When the researchers tested several AI models to predict the 'continuation' of a sentence, they found that Meta's '
[2505.12546] Extracting memorized pieces of (copyrighted) books from open-weight language models
https://arxiv.org/abs/2505.12546
Meta's Llama 3.1 can recall 42 percent of the first Harry Potter book
https://www.understandingai.org/p/metas-llama-31-can-recall-42-percent
The study, conducted by a team of computer scientists and legal scholars from Stanford, Cornell, and West Virginia Universities, investigated whether five AI models could reproduce the text of books included in the 'Book3' book dataset, which is often used to train large-scale language models (LLMs).
Book 3 contained the text of approximately 200,000 books, but it was deleted at the time of writing due to protests from anti-piracy groups that it contained copyrighted books.
The team picked five 'open weight models' for the experiment. An open weight model is a model that publishes the parameters 'weights' that the AI takes into account when determining the output. Knowing the weights has the advantage that the output result can be predicted without actually having the AI model output, which significantly reduces the cost of experiments.

When a large-scale language model determines an output, it 'predicts' the outcome using multiple parameters, including weights. AI expert Timothy Lee gives a good example of this:
A large-scale language model generates a word, lists multiple possible words that may come next after the generated word, and generates a probability distribution. For example, if you input the phrase 'peanut butter,' the large-scale language model will generate the following probability distribution:
Jam = 70%
・Sugar = 9%
・Peanuts = 6%
Chocolate = 4%
・Cream = 3%
After the large-scale language model generates a list of these probabilities, the system randomly chooses one of these options and weights it by its probability: 70% of the time 'peanut butter and jam' is chosen, 9% of the time 'peanut butter and sugar' is chosen, and so on.
The research team applied this to predict outcomes.
For example, if we wanted to estimate the probability that a model would answer 'peanut butter and jelly' to the question 'What is my favorite sandwich?', we would calculate it as follows:
Give a large-scale language model the text 'My favorite sandwich is' and find the probability that it will output 'peanuts.' Let's say it's 20%.
Enter 'My favorite sandwich is peanut' and find the probability that 'butter' will be output next (say 90%)
Enter 'My favorite sandwich is peanut butter' and find the probability of 'and' (say 80%)
Enter 'My favorite sandwich is peanut butter and jam' and find the probability of 'jam' (say 70%)
This gives us a probability of 0.2 x 0.9 x 0.8 x 0.7 = 0.1008, which means that there is roughly a 10% chance that this large-scale language model will return 'peanut butter and jelly' in response to the question 'My favorite sandwich is.'
This approach reduced research costs by eliminating the need for the AI to actually generate results.

The researchers took 36 books and split the text into sentences of 100 tokens each, fed the first 50 tokens as input prompts to a large-scale language model, and calculated the probability that the next 50 tokens it output would be word-for-word identical to the original sentence.
The team made this calculation quite rigorous: if even one out of 50 tokens was incorrect, it was deemed 'not the same,' and if the probability of the sentence being word for word was more than 50%, then the large-scale language model was able to reproduce the sentence.
The results of the test on 'Harry Potter and the Philosopher's Stone' are as follows. The five figures show the output results of five models, 'Pythia 12B', 'Phi 4', 'Llama 1 13B', 'Llama 1 65B', and 'Llama 3.1 70B', from the top, and the lines in the figure show the parts where the output matches the original text. Llama 3.1 70B matched 42% of the total.
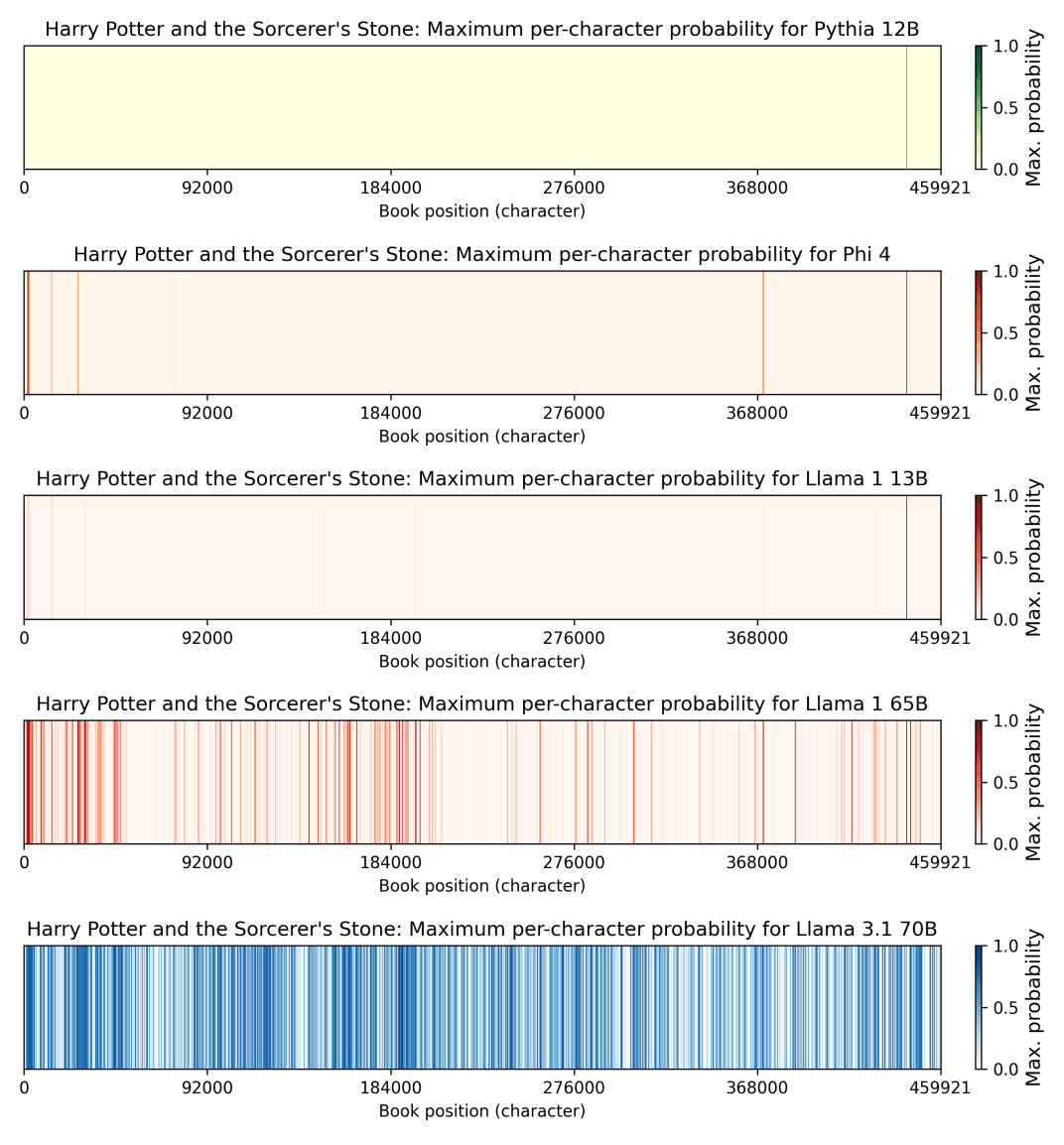
Llama 3.1 70B also showed similarly high matches to The
From these results alone, it is not possible to determine whether the entire text of 'Harry Potter and the Philosopher's Stone' was used to train Llama 3.1 70B, or only parts of it, or whether only 'quotes' from Harry Potter fan forums, book reviews, etc. were used. The high recall of Harry Potter and 1984 and the low recall of Sandman Slim could simply be due to the former being more popular and having more related content online.
Regarding the fact that recall rates vary widely between books, AI expert Lee points out that 'this could be a headache for law firms filing class action lawsuits against AI companies.'
Meta, the developer of Llama, is being sued for copyright infringement by three other authors, including Sandman Slim's author Kadley. Each of the three authors is suing for infringement of their own rights, but there is a restriction that the plaintiffs must be found to be in substantially similar legal and factual circumstances. In light of the results of this investigation, it is possible that the degree of infringement may vary greatly depending on the plaintiff. Lee argued that this could force the three authors to file lawsuits individually, which could work to Meta's advantage.

The AI industry argues that the use of copyrighted material in the training process is justified under the principle of 'fair use.' Regarding this, Lee pointed out, 'The fact that Llama 3.1 70B reproduced large parts of Harry Potter may influence how courts view such fair use issues. An important part of fair use is whether the use is 'transformative' - whether the company has created something new or is simply profiting from the copyrighted work of others. The fact that large-scale language models can reproduce large parts of popular works such as Harry Potter may lead judges to be skeptical of such fair use arguments.'
Cornell University law professor James Grimmelmann has noted that open weight models are more vulnerable to legal hazards than closed weight models. The success of this research was solely due to the disclosure of 'weights,' and if this research were to be the basis for a copyright infringement trial that worked against AI companies, there is a possibility that weights will no longer be disclosed in the future. AI companies are under no obligation to disclose weights, and most of them are disclosed in good faith in the hope of promoting the development of the AI industry.
'Copyright law may be a strong disincentive for companies to consider releasing open-weight models, while some judges may decide that it's wrong to effectively punish companies for releasing open-weight models,' Lee said. 'Some findings may support authors' claims, while others may be beneficial to defendants.'
Related Posts:








in Software, Posted by log1p_kr