AI research institute EleutherAI releases 'Common Pile v0.1', a massive dataset of about 8TB consisting only of public domain and open license content

EleutherAI, a non-profit AI research organization, in collaboration with the University of Toronto, Hugging Face, and others, has released the dataset ' Common Pile v0.1 ,' which is composed entirely of public domain and open license content. AI models 'Comma v0.1-1T' and 'Comma v0.1-2T,' trained on Common Pile v0.1, 'performed on par with models developed using unauthorized copyrighted data.'
[2506.05209] The Common Pile v0.1: An 8TB Dataset of Public Domain and Openly Licensed Text
The Common Pile v0.1 | EleutherAI Blog
https://blog.eleuther.ai/common-pile/
The Common Pile v0.1
https://huggingface.co/blog/stellaathena/common-pile
AI companies, including OpenAI, are embroiled in lawsuits over the methods they use to train AI models.
OpenAI's copyright lawsuit decides to disclose ChatGPT training data to some people, offline and recording devices prohibited under strict security system - GIGAZINE

Datasets used for AI training are often built by scraping information from the web, including copyrighted materials such as books and research journals. This has led to concerns that generative AI poses a risk of copyright infringement. While some AI companies have licensing agreements with certain content providers, most companies argue that the fair use principle, a U.S. legal principle, protects them from liability if they train their AI on copyrighted material without permission.
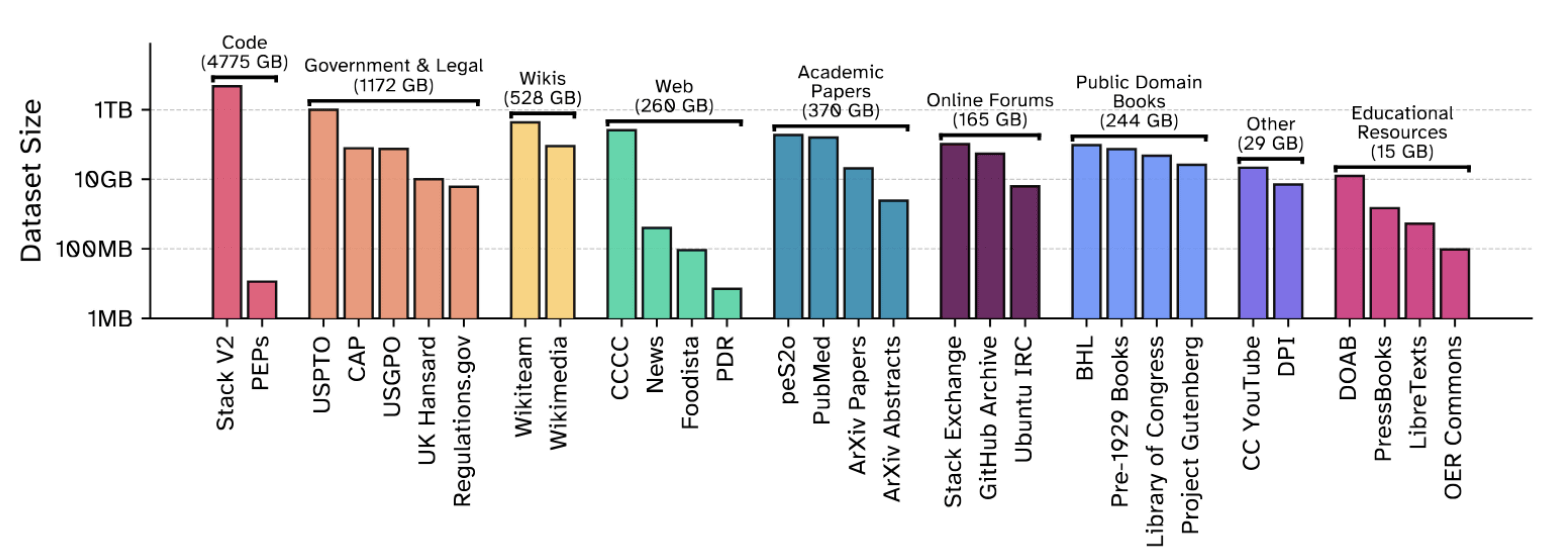
Common Pile v0.1 is the successor to the 800GB dataset ' The Pile ' released by EleutherAI in 2020. There are 30 types of datasets, totaling 8TB. The breakdown is as follows:
・Code (4775GB)
・Legal and government documents (1172GB)
・Texts such as Wikipedia (528GB)
・Academic Papers (370GB)
・Public domain books (244GB)
・Others include online forums, YouTube subtitles, educational resources, etc.
EleutherAI lists the goals and philosophies of Common Pile v0.1 as 'ensuring transparency and scientific rigor,' 'promoting openness,' and 'compliance with open licenses.' In particular, compliance with open licenses relies on the 'open license' criteria defined by
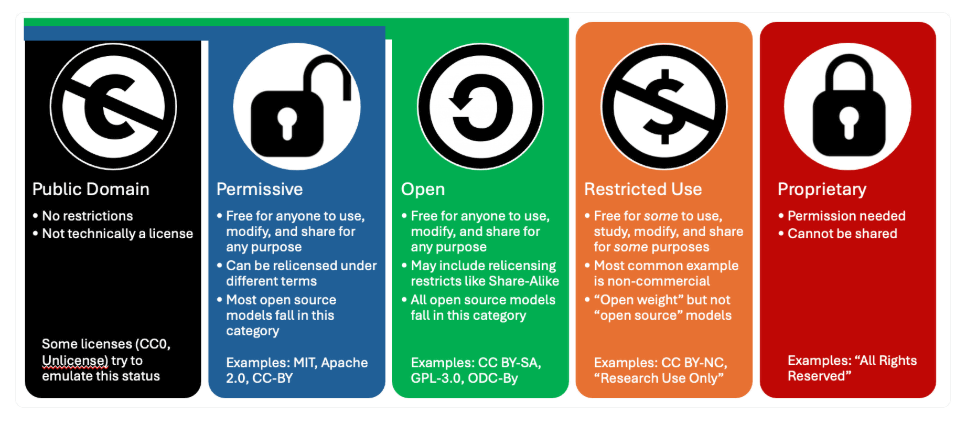
Whether the data we collect is openly licensed or not is verified through metadata from trusted sources and manual curation, rather than relying solely on automated tools.
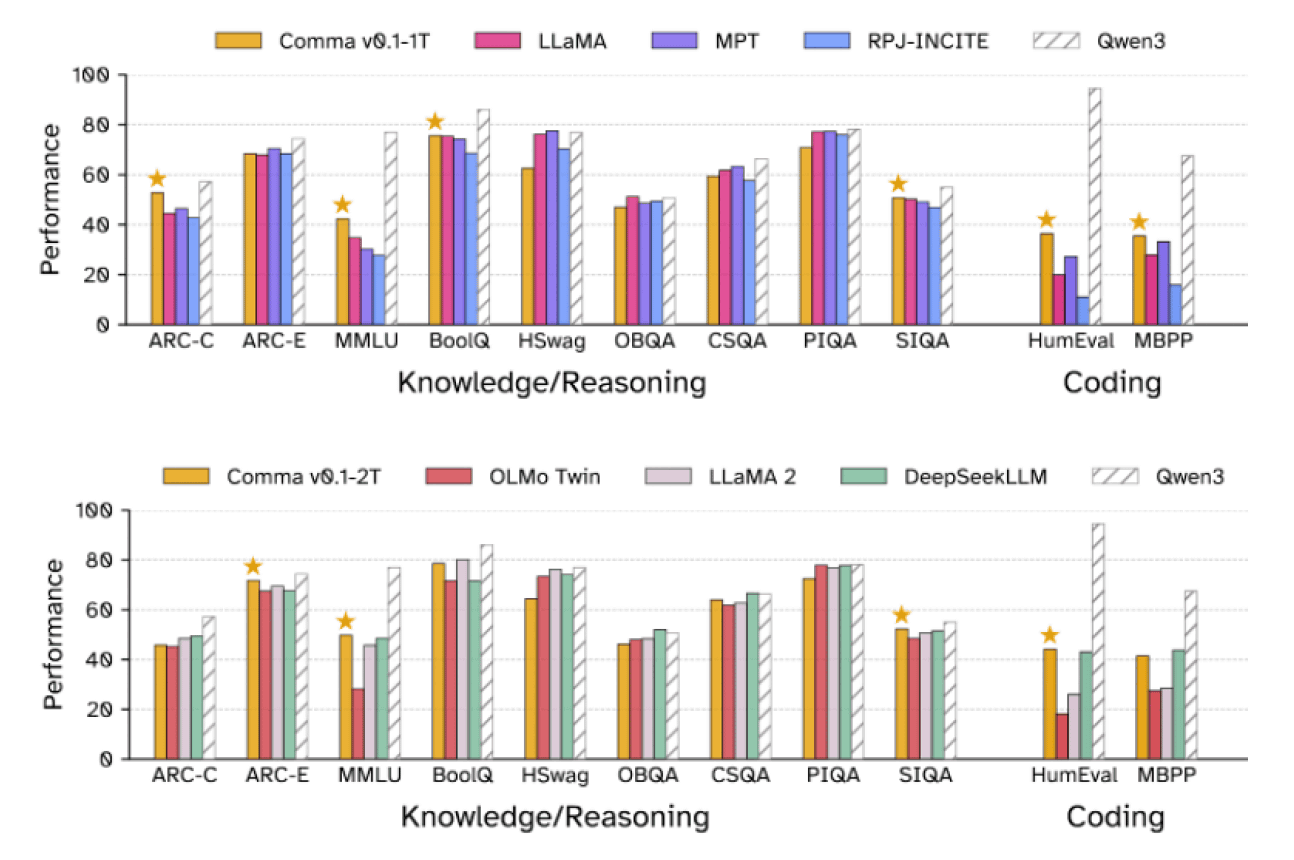
EleutherAI also showed that the 7 billion parameter language model 'Comma v0.1' trained on Common Pile has performance comparable to major models trained on unlicensed data. Below is a graph comparing the benchmark results of Comma v0.1-1T (top) and Comma v0.1-2T (bottom) with other AI models. Comma v0.1-1T was trained with 1 trillion tokens, and Comma v0.1-2T was trained with 2 trillion tokens.
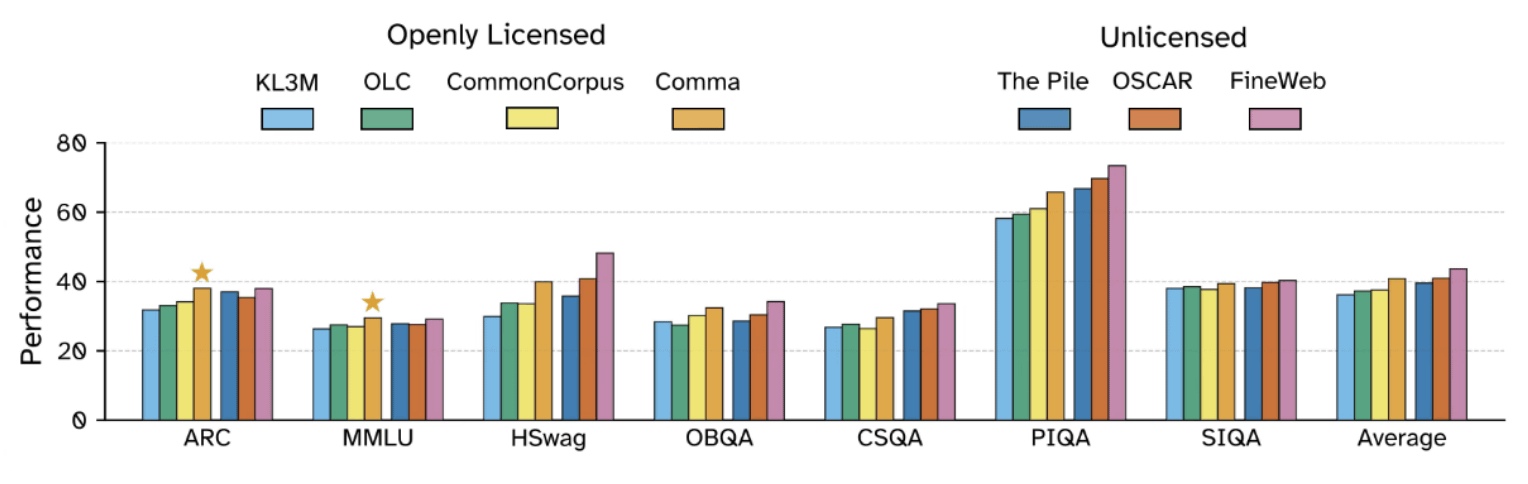
EleutherAI reported that 'the model trained on Common Pile performed as well as models trained on unlicensed datasets such as The Pile and OSCAR . However, it did not compare to FineWeb , which strictly filters only high-quality data from a very large data pool.'
'Calling this dataset 'Common Pile v0.1' is a very clear statement of intent. We're very excited about this release, but we see this as the first step, not the last. We want to build a bigger and better version, release openly licensed data that's not currently available, and give more back to the public,' said EleutherAI.
in Software, Posted by log1i_yk