How does an LLM work?

All chatbots that users can easily use, such as ChatGPT and Gemini, are built based on a technology called 'LLM (large-scale language model).' The YouTube channel '3Blue1Brown,' which uses animations to explain difficult topics in an easy-to-understand way, has made a video about how
Large Language Models explained briefly - YouTube
How LLM works (simple version) - YouTube
3Blue1Brown explains that 'large-scale language models are sophisticated mathematical functions that predict the next word in any given sentence.'
For example, let's say you have a script for a short movie that features a human and an AI assistant. The script includes a part where the human asks the AI a question, but there is no part where the AI answers.

Let's say you combine this script with a 'magical machine that can accurately predict the next word in any sentence.' Then, by inputting the script into the machine, you can predict the 'AI answer part.' The prediction starts from the first word, and by repeating it over and over again, you can predict the entire answer. This is exactly what happens when you interact with ChatGPT and the like.
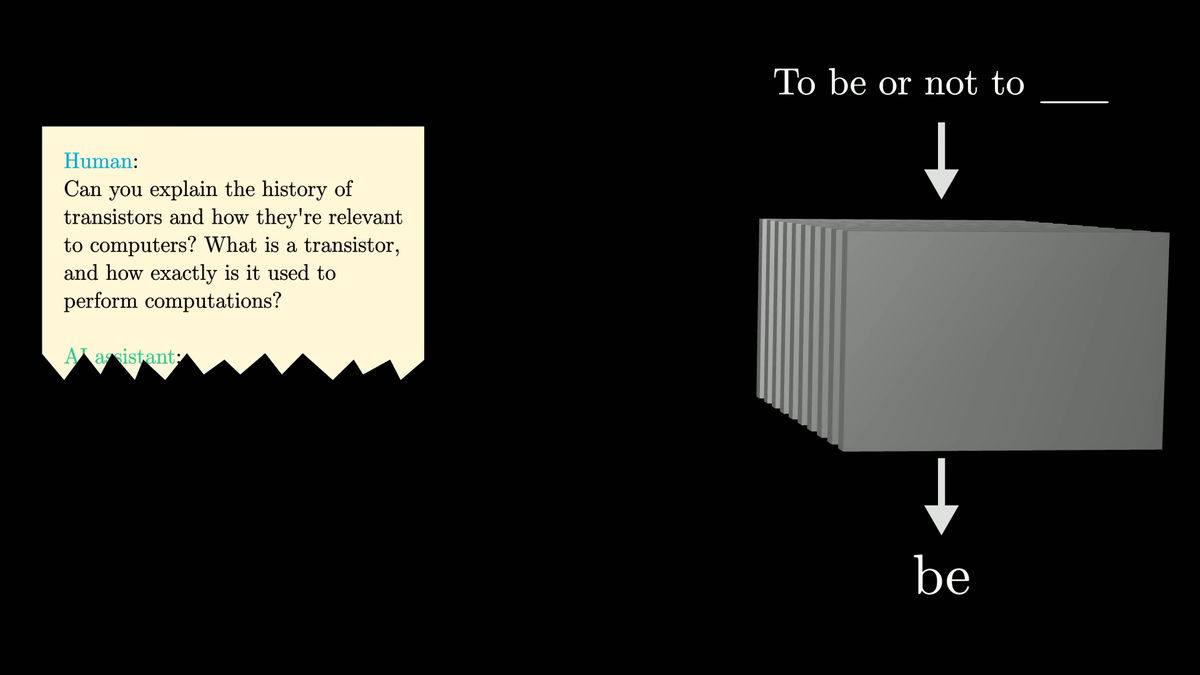
The chatbot starts with a text that shows a conversation between the user and a fictional AI assistant, then adds in user input. The model is then repeatedly run to predict the next words the fictional AI assistant is likely to say in response, and the resulting text is then displayed to the user in a batch.

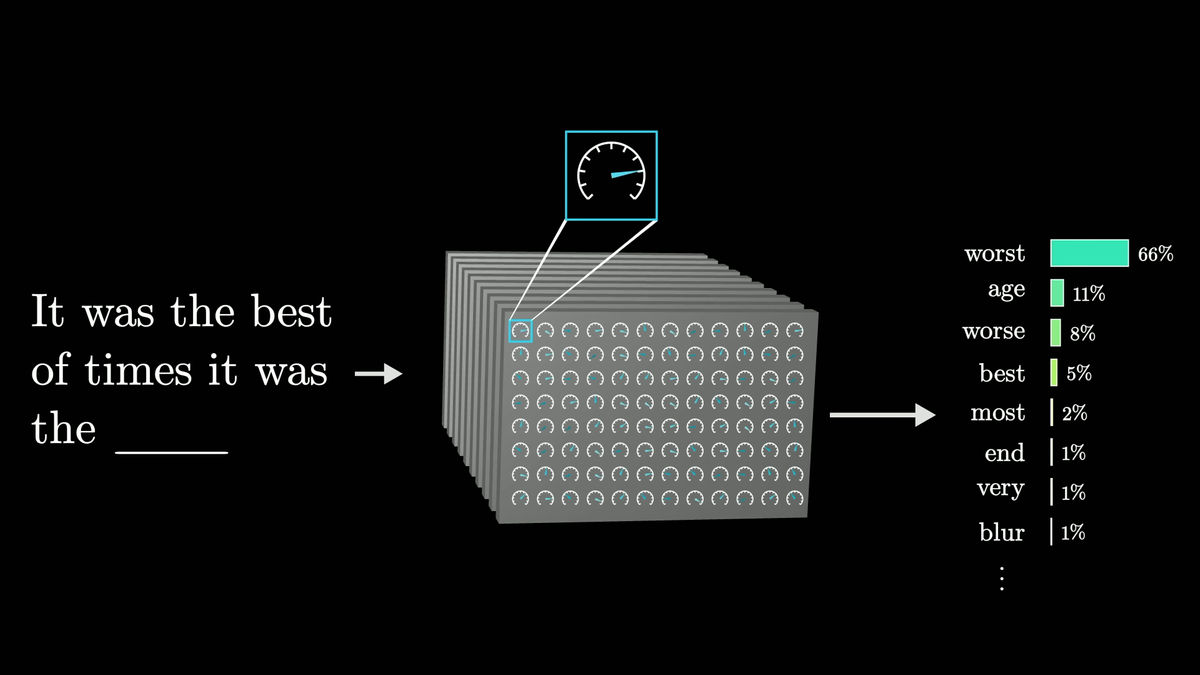
Instead of predicting exactly one next word, large language models enumerate all possible next words and assign a probability to each one. Selecting only high-probability words during generation will result in fewer errors, but allowing low-probability words to be chosen randomly also tends to make the output look more natural. This is why you might get different answers to the same prompt each time you run it.

Large language models essentially learn to make these predictions by processing vast amounts of text collected from the internet. If a standard human were to read the amount of text used to train OpenAI's LLM GPT-3, it would take them more than 2600 years of continuous reading time. Furthermore, newer LLMs have been trained on much more data.

You can think of learning as adjusting the dials of a large machine. Large-scale language models have parameters called 'weights,' and changing these parameters changes the probability of the output for a particular input. The 'large' part of large-scale language models is that there are hundreds of billions of these parameters. Humans do not intentionally set these parameters; the model refines itself through repeated input and output.
Training works by feeding the model sentences minus the last word, and comparing the predictions it makes to the actual answers. We make adjustments to reduce the error, making the model a little more likely to choose the correct answer from its predicted words, and a little less likely to choose other words. When we do this for trillions of sentences, the model not only becomes accurate on the training data, but also makes reasonable predictions on sentences it has never seen before.

Learning requires calculations using a huge number of parameters and training data, and much of this calculation is performed by GPUs, which can process multiple operations in parallel. In 2017, a team of Google researchers announced a learning model called

However, this alone does not make it usable as a chatbot. Even if it can predict the continuation of random sentences on the Internet, it does not become a good AI assistant. To build a chatbot based on a large-scale language model, in addition to the 'pre-learning' process described above, 'reinforcement learning' with feedback from humans is required.

In reinforcement learning with human feedback, bad or problematic predictions are manually flagged, and those corrections further modify the model's parameters to make predictions that the user prefers.

3Blue1Brown summarizes, 'It's very hard to tell why a model makes a particular prediction, because the model's output is determined by tuning the parameters during training. What we do know for sure is that the language that large-scale language models produce is eerily smooth, engaging, and even useful.'