How fast is Google's diffusion language model 'Gemini Diffusion'?
The AI model '
Gemini Diffusion
https://simonwillison.net/2025/May/21/gemini-diffusion/
General language models use a technique called an autoregressive model , which generates text one token at a time. On the other hand, Gemini Diffusion uses a diffusion model, which is widely used in image generation models, and operates by 'stepwise refining noise and outputting the final product.' This enables extremely fast processing and also has the advantage of being able to 'correct errors during the generation process.'
Google DeepMind announces Gemini Diffusion, a diffusion model that generates text at explosive speeds - GIGAZINE

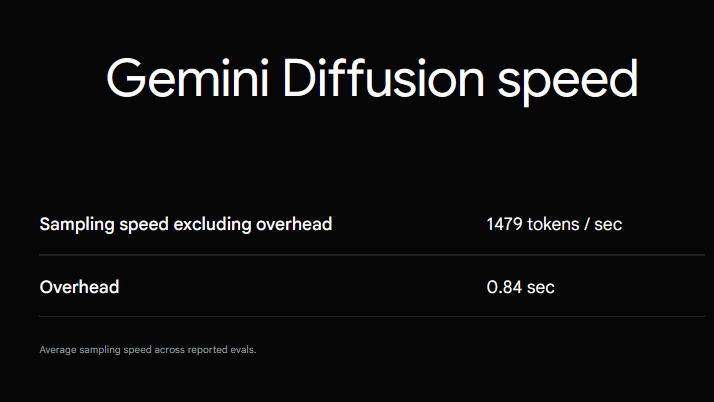
Google claims that Gemini Diffusion can generate 1,479 tokens of text per second.
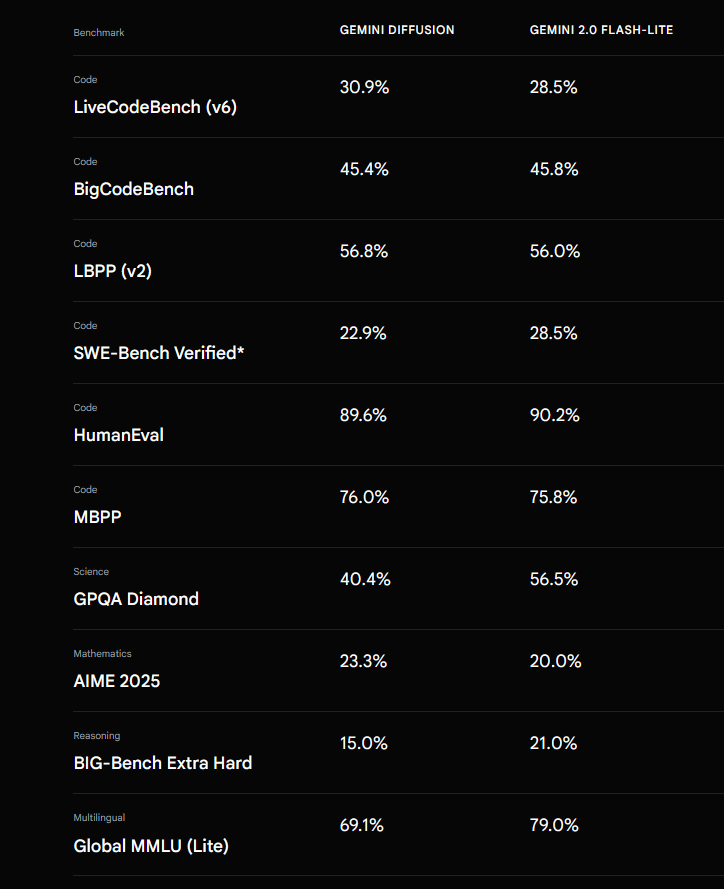
Gemini Diffusion is also very fast, recording benchmark scores comparable to
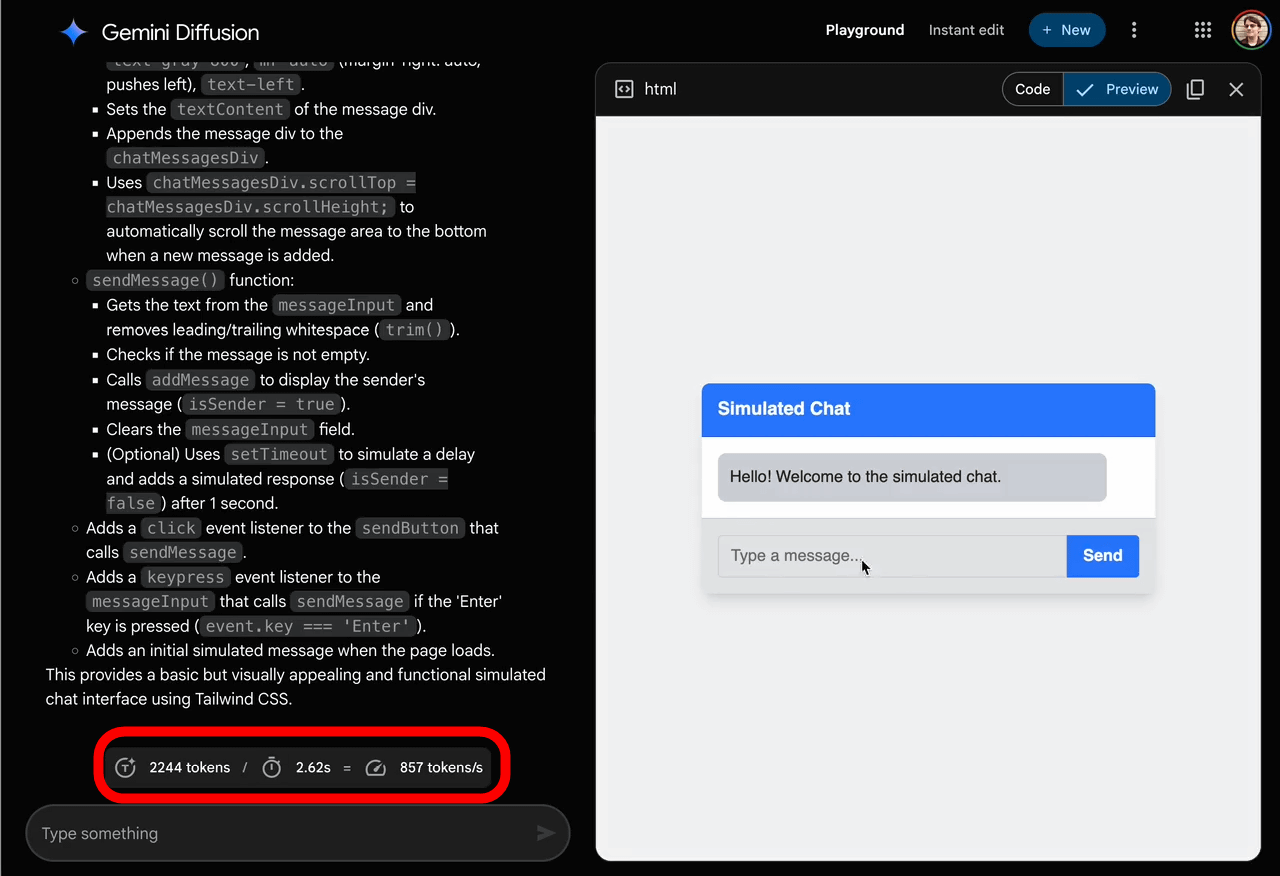
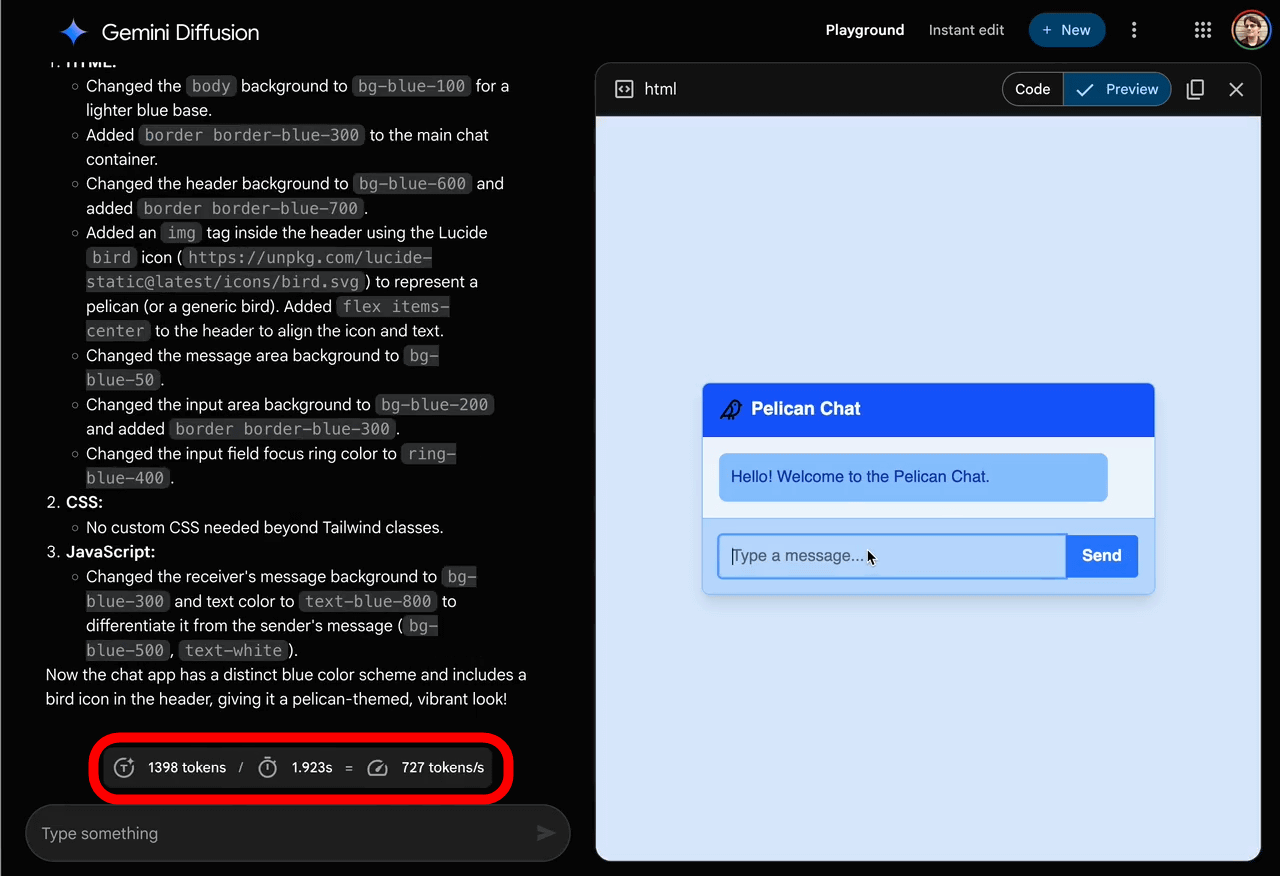
When I typed 'build a simulated version of a chat app,' the code was generated at high speed and a preview was displayed on the right side of the screen. The bottom left of the screen states that 857 tokens were generated per second. The preview displayed includes the 'function to enter text' and the 'function to display the entered text in a chat-like format,' which shows that the given task is being performed accurately.
In addition, when asked to 'build a Pelican version of the chat app,' the code was generated at a lightning-fast rate of 727 tokens per second.
By the way, the idea of building a language model using a diffusion model is not new. In February 2025, AI development company Inception announced the high-speed diffusion language model 'Mercury Coder,' which has attracted attention.
'Mercury Coder' is a diffusion-type language model that can extract words from noise and generate explosive code - GIGAZINE
On the same day as the announcement of Gemini Diffusion, Google also announced Gemma 3n, a lightweight multimodal AI model that runs locally on smartphones. Gemma 3n uses an autoregressive model similar to conventional language models, rather than a diffusion model, but its main feature is the adoption of Per-Layer Embeddings (PLE), a technology that contributes to reducing memory usage, making it possible to run locally even on smartphones with low memory capacity. The steps to actually run Gemma 3n on a smartphone are explained in detail in the following article.
Introducing the Google-made open source AI model 'Gemma 3n' that runs locally on smartphones, here's how to use it on your smartphone right now - GIGAZINE
Google has also made a major update to Google AI Studio , adding new features such as code generation with Gemini 2.5 Pro, automatic reading with over 30 voices, and support for the Model Context Protocol (MCP) .
An upgraded dev experience in Google AI Studio - Google Developers Blog
https://developers.googleblog.com/en/google-ai-studio-native-code-generation-agentic-tools-upgrade/
Related Posts:






in Software, Posted by log1o_hf