What is the difference between ChatGPT's 'Deep research' and Gemini's 'Deep Research'?

AI companies such as Google, OpenAI, Perplexity, DeepSeek, and xAI each implement their own 'Deep Research' feature. Machine learning engineer
The Differences between Deep Research, Deep Research, and Deep Research
https://leehanchung.github.io/blogs/2025/02/26/deep-research/
In December 2024, Google announced 'Deep Research,' an information-organizing AI function that follows user instructions to collect information from the Internet that will help solve problems.
Google releases 'Deep Research', an AI function that collects information on behalf of humans, and compiles a huge amount of information on the web and submits a report - GIGAZINE

In February 2025, OpenAI announced a feature called 'Deep research' that allows ChatGPT to collect online information.
OpenAI announces that ChatGPT will have a 'Deep research' feature that allows it to collect online information - GIGAZINE
Perplexity has also announced a ' Deep Research ' feature that conducts in-depth research and analysis on users' behalf.
Other AI companies such as DeepSeek, Qwen, and xAI have also developed 'Deep Research' search functions for chatbots, and there are dozens of open source implementations on GitHub that mimic these Deep Research functions.
'Deep Research' is a report generation system that takes user queries, iteratively searches and analyzes information using large-scale language models (LLMs) as agents, and generates detailed reports as output. In natural language processing (NLP) terms, this is called 'report generation'.
This 'report generation' has been attracting attention in the industry since ChatGPT announced the 'Deep research' feature in February 2025, but it seems that Lee had personally experimented with the system as of early 2023 when AI engineering began.
As for why report generation has not received much attention until now, Lee explains that 'it was not practical to ask early LLMs like GPT-3.5 to generate reports.' Since report generation was not practical for LLMs at the time, a composite pattern of 'invoking and concatenating multiple LLMs' was adopted instead.
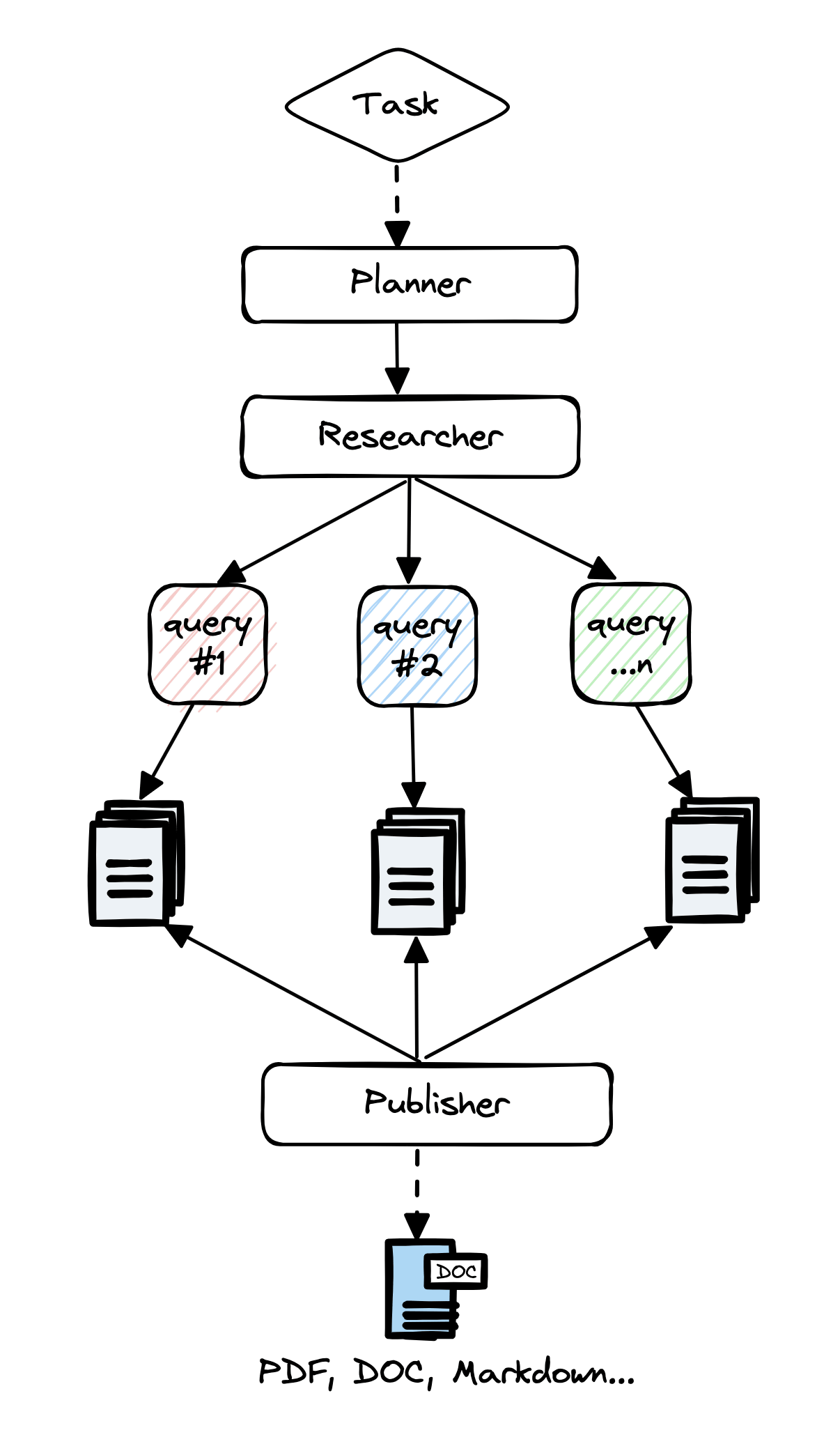
The composite pattern process is as follows. A representative example of a composite pattern is GPT Researcher . The composite pattern has the problem of inconsistent quality of reports because the output is 'dependent on subjective visual inspection.'
1: Break down user queries and create report outlines.
2: For each section, retrieve and summarise relevant information from search engines and knowledge bases.
3: Prepare a report that integrates sections using LLM.
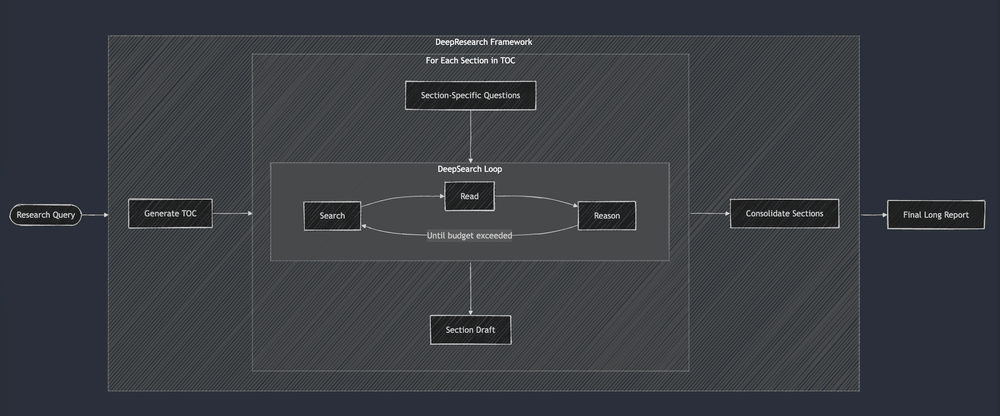
To improve the quality of the reports generated by the composite pattern, engineers added complexity to the DAG approach. Instead of a single path process, they introduced structural patterns such as
Then came Stanford's STORM , which used DSPy to optimize its system end-to-end to produce reports of Wikipedia article quality.
STORM
https://storm.genie.stanford.edu/
The above advances have made large-scale inference models an attractive option for the Deep Research function, Lee explains. Regarding the method of training the models used in Deep Research, OpenAI explains that 'we use LLMs as judges and use evaluation criteria to evaluate the output.'
On the other hand, Google and Perplexity have not published any literature on how they optimized their models or systems or any substantial quantitative evaluations in their 'Deep Research' feature. However, a Google product manager explained in a podcast interview , 'We have special access. It's almost the same model (Gemini 1.5). Of course, we do our own post-training work.' On the other hand, xAI's 'Deep Research' feature is good at generating reports, but it doesn't search beyond two iterations.
Lee created a map to rate each AI's 'Deep Research' capabilities. The vertical axis measures the depth of search, defined as 'the number of iterative cycles the service performs to gather additional information based on previous findings.' The horizontal axis rates the level of training, with the farther left the more manually tuned the system is, and the farther right the more fully trained the system is using machine learning techniques.

in Software, Posted by logu_ii